ククログ
2010年
昨年は多くの方々にお世話になりました。ありがとうございます。 今年もどうぞよろしくお願いします。

早いもので、クリアコード設立から約3年半、ククログ開始から約1年半が経過しました。うまくいくことばかりではありませんでしたがこれまでやってこれました。
クリアコードは小さな受託開発の会社で、1人を除いて全員開発者です。すべての開発者はフリーソフトウェアの開発に関わっており、そこでの経験を活かして受託開発をしています。
フリーソフトウェアの開発で学んだことの1つに「いきなりとてもよくすることは難しい」ということがあります。細かいバグ修正の積み重ねがより安定したソフトウェアにつながり、細かい機能追加・改良がより使いやすいソフトウェアにつながる、ということを実際に開発に参加しながら実感してきました。
大きな機能追加も小さなコミットの積み重ねです。最初は「とりあえず動く」だったものが、コミットの積み重ねで便利で安定した機能になっていく過程を何度も体験しました。新機能・改良の提案もいきなり大きなパッチを提出するのではなく、1つずつ小さな提案を積み重ねて、最終的によりよいソフトウェアとなることを目指します。その過程で、当初想定していた方法とは違う方法で実現されることも珍しくありません。それは、他の開発者とやりとりをし、よりよい実現方法を見つけることがあるからです。
今年のクリアコードも、ソフトウェア開発や多くの方々とのやりとりなどからいろいろなことを学び、少しずつよりよくなっていく予定です。意識しないと気づかない程度になってしまうかもしれませんが、少しずつよくなっていくクリアコードを今年もお楽しみください。
あしたのオープンソース研究所: GStreamer
先日、あしたのオープンソース研究所の第6回でオープンソースのマルチメディアフレームワークであるGStreamerを紹介してきました。

あしたのオープンソース研究所では、海外のオープンソースソフトウェアのドキュメントを翻訳されていて、翻訳対象の文書も募集されています。GStreamerなどいくつか応募したのですが、そのうちの1つとしてGStreamerを採用してもらえたのでGStreamerの概要を紹介をしてきました。
スライドを見ただけでは伝わらないはずなので少し説明も加えておきます。いくつか省略しているページもあるので、完全版が見たい場合は画像のリンク先を見てください。
GStreamerとは

GStreamerはマルチメディアのフレームワークです。音声・動画の再生、フォーマットの変換、録音・録画など基本的なことはもちろん、RTSPなどを用いたネットワーク通信を行うこともできます。
使い方
GStreamerにはgst-launchというコマンドラインツールが付属していて、gst-launchを使うことによりプログラムを作らなくてもGStreamerの機能を利用することができます。

GStreamerにはplaybinという機能があり、再生するときはこの機能が便利です。URIを指定するだけで、内容からフォーマットを自動で判別し、フォーマットに合わせた再生処理をします。音声・動画どちらでも再生することができます。

GStreamerではshのパイプのように機能をつなぎ合わせて目的を実現します。Ogg VorbisからAACへフォーマットを変換する場合は、以下のように機能を組み合わせます。
- ファイルから読み込み(filesrc)
- OggコンテナからVorbisデータを取り出し(oggdemux)
- Vorbisデータをデコード(vorbisdec)
- 音声データのフォーマットを微調整(audioconvert)
- AACでエンコード(faac)
- AACデータをMP4コンテナに格納(ffmux_mp4)
- ファイルへ書き込み(filesink)

GStreamerはVideo4Linuxにも対応しているので、Linux環境ではVideo4Linuxを利用してPCに接続されたWebカメラで録画することもできます。ここでは以下のように機能を組み合わせて、Webカメラで撮影した動画を画面に出力しています。
- Video4LinuxでWebカメラから撮影した動画を取り込み(v4l2src)
- 動画を画面に出力(autovideosink)
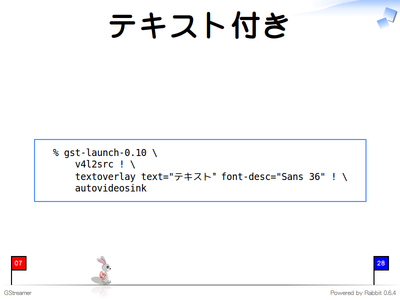
撮影した動画を画面に出力する前にテキストを挿入することもできます。GStreamerでは機能をつなぎ合わせて目的を実現するので、間に追加の機能を挿入することが簡単にできます。
- Video4LinuxでWebカメラから撮影した動画を取り込み(v4l2src)
- [追加] 動画にテキストを挿入(textoverlay)
- 動画を画面に出力(autovideosink)

動画と合わせて音声も録音することができます。動画用のパイプライン(機能のつなぎ合わせ)と音声用のパイプラインが別々になっていることがポイントです。

GStreamerでは機能を付け替えることが簡単にできるため、データの入力元・出力先をファイルからネットワーク通信に変えてやることで別のホストに動画を転送することもできます。この例ではRTPなどを使わず、直接TCPでOggデータをやりとりしています。まず、データを受信して画面に表示するクライアント側を動かします。
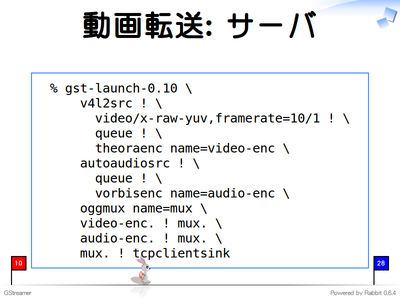
別の端末で録画したものをOggにエンコードしてクライアント側にTCPでデータを送信します。Theoraにエンコードしている部分で「video/x-raw-yuv,framerate=10/1」としているのは、フレームレートをおとしてデータ量を減らすためです。

サーバ側・クライアント側で何もデータを変換しなければネットワーク経由でのファイルコピーも実現できます。GStreamerは機能をつなぎ合わせるための汎用的な環境を提供しているので、こんなこともできるよ、という話です。
GStreamerでどういうことができるのかというイメージをつかめたでしょうか。
GStreamerの周辺

GStreamerはGNOMEアプリケーションで利用されています。メディアプレイヤーのTotem、音楽プレイヤーのRhythmbox、CDリッパーのSound Juicer、VoIP・ビデオ会議アプリケーションのEkigaなどはGStreamerを利用しています。GStreamerはGNOMEアプリケーション以外でも利用されています。FlashプレイヤーのGnashや動画編集ソフトのPiTiVi、Mozillaテクノロジーをベースとした音楽プレイヤーであるSongbirdなどもGStreamerを利用しています。

GStreamerと類似しているソフトウェアにはFFmpeg、Phonon、QuickTime、DirectShowなどがあります。どれもマルチメディアを扱うソフトウェアなのでGStreamerと似ているのですが、GStreamerはこれらのソフトウェアと競合するものではありません。
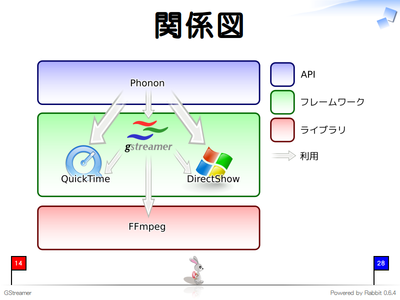
これらのソフトウェアの関係を図示したものです。ここでは、「API」、「フレームワーク」、「ライブラリ」という層に分けていますが、一般的な分け方ではないので注意してください。実際、複数の層にまたがるソフトウェアが多く、この分類にすっきり当てはまるわけではありません。ただ、このようにざっくりと分類した方がイメージがつかみやすいのではないかということでこのような分類を導入しました。
上の層ほど高レベルのソフトウェアで下の層のソフトウェアを利用したりして実現されています。それぞれの層は以下のように分類しています。
ライブラリ層はコーデックなどマルチメディアデータのフォーマットを扱う機能などを提供します。GUIがないことが多く、プログラムや付属のコマンドラインツールなどからライブラリの機能を利用することになります。1つのライブラリで必要な機能がすべて満たされる場合はこの層を直接利用するとよいでしょう。複数のライブラリが必要になる場合は、フレームワーク層やAPI層を利用した方が開発効率がよくなることが多いです。この層にあるソフトウェアは、サーバ上でも広く利用されているFFmpegやTheoraをエンコード・デコードする機能を提供するlibtheoraなどの各種コーデック、などです。
フレームワーク層はメディアフォーマットのエンコード・デコード機能だけではなく、複数のフォーマットを統一的に扱う機能や、マルチメディア再生時の制御機能など、メディアプレイヤーで必要になるようなマルチメディア関連の機能を包括的に提供します。フレームワークに後から機能(コーデックなど)を追加する仕組みがあることが多く、この仕組みにより、プログラムの変更を最小限に抑えながらアプリケーションを新しいフォーマットに対応させたりすることができます。より汎用的なアプリケーションを開発する場合はこの層を使って開発するとよいでしょう。この層にあるソフトウェアは、GStreamerやMac OS XのQuickTime、WindowsのDirectShowなどです。
API層は実際の処理を行わず、フレームワークやライブラリを利用してプログラマが安心してマルチメディア機能を使うための安定したAPIを提供する層です。プログラマがAPI層を利用する利点は、環境(やフレームワークやライブラリ)に依存せずに同じコードでマルチメディアの機能を利用できることです。この層にあるソフトウェアはQtに含まれているPhononやMac OS XでのQTKitです。QtプログラマはPhononが提供するAPIを用いてプログラムを開発することで、クロスプラットフォームで動作するマルチメディア機能を実現することができます*1。
GStreamerが他のソフトウェアと競合しないのは、GStreamerが他のソフトウェアの機能を利用できるからです。GStreamerは、後からGStreamerに機能を追加できるプラグインシステムを実装しています。プラグインシステムを用いて、FFmpegの機能を利用したり、Mac OS XではQuickTimeの機能を利用したり、WindowsではDirectShowの機能を利用したりできます。つまり、GStreamerは他のソフトウェアと協調して動作することができます。このため、他のソフトウェアと競合しないのです。
GStreamerの仕組み
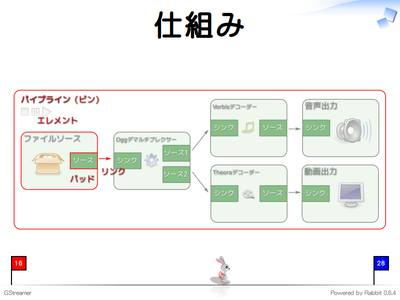
GStreamerの概要を理解するために大事な概念は以下の4つです*2。
- エレメント
- リンク
- パッド
- パイプライン(ビン)
エレメントが個々の機能に対応します。エレメントにはデータの出入り口となるパッドがあります。エレメントから別のエレメントにデータを渡す場合は、エレメント同士を接続しなければいけません。これをリンクといいます。エレメント同士を接続するときは、パッドとパッドを接続します。
エレメントをつなぎ合わせて目的とする機能を実現したら、エレメントをパイプラインに入れます。パイプラインに入れると、エレメントの処理の開始・停止などを一括で指示できるようになります。それぞれのエレメントに対して指示する必要はありません。
エレメントはパッドの持ち方で以下の3種類に分類できます。
- ソースエレメント
- フィルタエレメント
- シンクエレメント
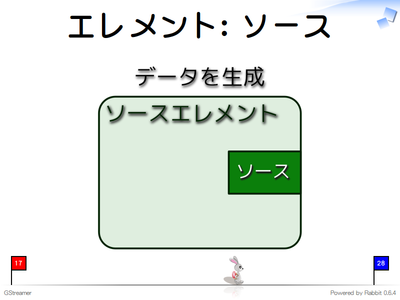
ソースエレメントはデータ出力用のパッド(ソースパッド)のみを持つエレメントです。データ生成用のエレメントで、エレメントのつなぎ合わせの先頭におきます。ファイルからデータを読み込むエレメントなどがソースエレメントです。
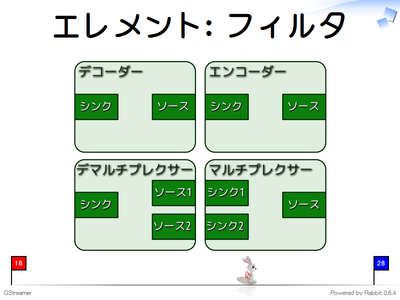
フィルタエレメントはデータの入力用パッド(シンクパッド)と出力用パッド(ソースパッド)を持つエレメントです。入力用と出力用のパッドを1つずつ持つエンコーダーやデコーダーのようにデータを変換するエレメントがあります。エレメントはパッドを複数持つことができます。マルチプレクサーは複数の入力から1つのコンテナフォーマットのデータを生成し、デマルチプレクサーは1つのコンテナフォーマットのデータを分解し、複数の出力データを生成します。

シンクエレメントはデータ入力用のパッド(シンクパッド)のみを持つエレメントです。データ受信用のエレメントで、エレメントのつなぎ合わせの最後におきます。ファイルにデータを出力するエレメントなどがシンクエレメントです。
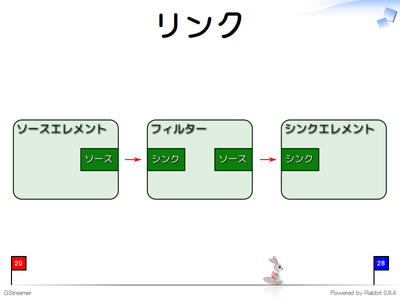
目的の機能を実現するためにはソースエレメント→フィルタエレメント→…→フィルタエレメント→シンクエレメントというようにリンクします。
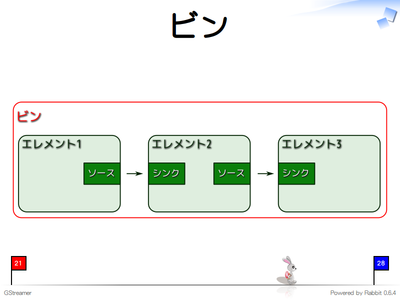
リンクしたエレメントはビン(パイプライン。パイプラインはビンの1種)に入れて利用します。
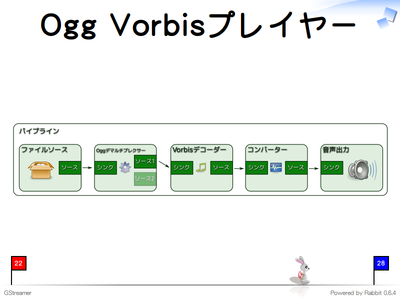
例えば、Ogg Vorbisを再生する場合はこのようにエレメントをリンクします。
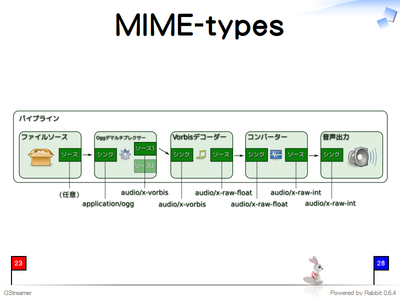
どのエレメント同士もリンクできるわけではありません。パッドは受け付けられるMIME-typeを複数持っています。パッド同士が同じMIME-typeを利用する場合のみエレメントをリンクできます。
Ogg Vorbisプレイヤーの場合はこのようなMIME-typeのパッドでリンクしています。
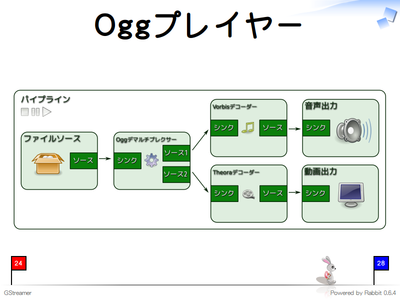
Ogg Vorbis/Theoraプレイヤーはこのようになります。Oggデマルチプレクサーからの出力を両方とも利用しています。
まとめ

GStreamerはマルチメディアフレームワークで、マルチメディアを扱う場合に必要な機能が一通り揃っていて、GNOMEアプリケーションなど多くのアプリケーションで利用されていています。PhononやQuickTimeなど類似のソフトウェアがありますが、GStreamerはそれらと競合するソフトウェアではなく、それらと協調して動作します。

GStreamerにはエレメントとパッドとビンという概念があります。
エレメントはデータを処理するもので、複数のエレメントをつなぎ合わせて目的の機能を実現します。エレメント同士をつなぎ合わせることをリンクといい、エレメントをリンクするときはエレメントのパッドとパッドをつなぎ合わせます。リンクしたエレメントをビン(パイプライン)に入れて目的の機能を利用します。

ここではGStreamerの概要のみを扱ったので、省略したことがたくさんあります。
あしたのオープンソース研究所ではGStreamerのチュートリアルを翻訳してくれるそうです。チュートリアルにはここで説明したことより多くのことが書かれているので、GStreamerに興味を持った方はチュートリアルも読んでみてください。翻訳は1,2ヶ月後には公開されているようなので、2月か3月になると日本語でチュートリアルが読めるのではないでしょうか。楽しみですね。
解説付きで資料を公開してみました。スライド中で使っているSVGの画像やRabbitのソースもあわせて公開しました*3。もし利用する場合ははじめにCOPYINGに書かれたライセンスを確認してください。
Debianパッケージの作り方と公開方法: groongaを例にして
注: Debianデベロッパーが書いた文章ではありません。Debianデベロッパーになりたい方はDebianが公式に配布している文書の方をお勧めします。
Web上にはいくつかDebianパッケージの作り方を説明しているページがありますが、はじめてDebianパッケージを作る場合には情報不足のものが多いです。例えば、古めの文書でCDBSを使っていなかったり、「あとは適当に修正して…」などと手順の一部が省略されている文書が多いです。
ここでは、全文検索エンジン兼カラムストアのgroongaを例にしてDebianパッケージの作り方を説明します。ここで説明するのは、1つのソースから1つのパッケージを作成するのではなく、1つのソースから複数のパッケージを作成する方法です。この方法は、ライブラリの場合に多く用いられます。
また、aptitudeでインストールできる形で公開する方法もざっくりと紹介します。ここで作成するDebianパッケージは以下のようにインストールすることができます。
- Debian/GNU Linux lenny
-
以下の内容の/etc/apt/sources.list.d/groonga.listを作成
deb http://packages.clear-code.com/debian/ lenny main deb-src http://packages.clear-code.com/debian/ lenny main
インストール:
% sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 1C837F31 % sudo aptitude update % sudo aptitude -V -D -y install groonga libgroonga-dev
- Debian/GNU Linux sid
-
以下の内容の/etc/apt/sources.list.d/groonga.listを作成
deb http://packages.clear-code.com/debian/ unstable main deb-src http://packages.clear-code.com/debian/ unstable main
インストール:
% sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 1C837F31 % sudo aptitude update % sudo aptitude -V -D -y install groonga libgroonga-dev
- Ubuntu 8.04 LTS Hardy Heron
-
注: Ubuntu本家のuniverseセクションもインストール対象としておくこと
以下の内容の/etc/apt/sources.list.d/groonga.listを作成
deb http://packages.clear-code.com/ubuntu/ hardy universe deb-src http://packages.clear-code.com/ubuntu/ hardy universe
インストール:
% sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 1C837F31 % sudo aptitude update % sudo aptitude -V -D -y install groonga libgroonga-dev
- Ubuntu 9.10 Karmic Koala
-
注: Ubuntu本家のuniverseセクションもインストール対象としておくこと
以下の内容の/etc/apt/sources.list.d/groonga.listを作成
deb http://packages.clear-code.com/ubuntu/ karmic universe deb-src http://packages.clear-code.com/ubuntu/ karmic universe
インストール:
% sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 1C837F31 % sudo aptitude update % sudo aptitude -V -D -y install groonga libgroonga-dev
それでは、まずはパッケージの作り方です。
パッケージの作り方
dh_makeを利用する方法が紹介されていることが多いですが、dh_makeではたくさんのファイルが生成されるため、はじめてパッケージを作成する場合はとまどってしまいます。そのため、ここでは手動でパッケージを作成する方法を紹介します。
構成
groongaはライブラリとgroongaのデータベースを管理するコマンドで構成されています。この場合、Debianでは以下のように複数のパッケージに分解します。
- libXXX: ライブラリを使用しているソフトウェアを実行するために必要なファイルを提供するパッケージ。/usr/lib/libXXX.soなどを提供する。
- libXXX-dev: ライブラリを使用しているソフトウェアをビルドするために必要なファイルを提供するパッケージ。/usr/include/XXX/*.hなどを提供することが多い。libXXXに依存する。
- XXX: (ライブラリではなく)コマンドを提供するパッケージ。libXXXに依存する。
groongaの場合は以下のようなパッケージを作成することとします。
- libgroonga: /usr/lib/libgroonga.soを提供。
- libgroonga-dev: /usr/include/groonga/*.hと/usr/lib/pkgconfig/groonga.pcを提供。
- groonga: /usr/bin/groongaを提供。
ソースのファイル名
Debianパッケージを作成する場合にはじめにつまずくポイントがファイルやディレクトリの名前付けの規則です。今回は現時点での最新リリースgroonga 0.1.5を利用するので、それを例にして説明します。
まず、元のソースをダウンロードし、展開します。
% cd /tmp % wget http://groonga.org/files/groonga/groonga-0.1.5.tar.gz % tar xvzf groonga-0.1.5.tar.gz groonga-0.1.5/ ...
この状態ではDebianの名前付け規則から外れています。規則に合わせるためには以下のようにします。
% mv groonga-0.1.5.tar.gz groonga_0.1.5.orig.tar.gz
つまり、以下のような構成にする必要があります。
. |--- groonga-0.1.5/ | |... | ... +--- groonga_0.1.5.orig.tar.gz
一般化するとこうです*1。
- ソースのディレクトリ名: #{パッケージ名}-#{バージョン}
- ソースのアーカイブ名: #{パッケージ名}_#{バージョン}.orig.tar.gz
debian/
ソースの準備ができたら、ソースを展開したディレクトリの直下にdebian/ディレクトリを作成します。Debianパッケージ用のファイルはこのディレクトリの下に置きます。
% cd groonga-0.1.5 % mkdir debian/
このような構成になります。
. |--- groonga-0.1.5/ | |--- debian/ | | |... | |... | ... +--- groonga_0.1.5.orig.tar.gz
今回のパッケージ作成に必要なファイルは以下の通りです。それぞれ順番に説明します。
- debian/control
- debian/rules
- debian/copyright
- debian/changelog
debian/control
debian/controlにはパッケージ全体の情報と個々のパッケージの情報を書きます。
まず、パッケージ全体の情報です。
Source: groonga Priority: optional Maintainer: Kouhei Sutou <kou@clear-code.com> Build-Depends: debhelper (>= 5), cdbs, autotools-dev, libmecab-dev Standards-Version: 3.7.3 Homepage: http://groonga.org/
それぞれ以下のような意味です。
- Source
- パッケージの元になるソースの名前
- Priority
- パッケージの優先度。自作パッケージはoptional。
- Maintainer
- パッケージメンテナー
- Build-Depends
- パッケージを生成するときに利用するパッケージ。debhelperとcdbsは必須。groongaはAutotoolsとMeCabを利用しているため、auttools-devとlibmecab-devも加えている。
- Standards-Version
-
パッケージが準拠しているDebianポリシーマニュアルのバージョン。現在の最新バージョンは3.8.3。
3.7.3を指定しているのはUbuntu 8.04 LTS Hardy Heron用にもパッケージを作成するため。Hardyの時点ではバージョンが3.7.3だった。
- Homepage
- パッケージのWebサイト。ソースが入手できるようなサイト。
次に、個々のパッケージの情報を書きます。ここでは、libgroonga-devパッケージを例にして説明します。他のlibgroonga, groongaパッケージは後で示します。
Package: libgroonga-dev
Section: libdevel
Architecture: any
Depends: ${misc:Depends}, ${shlibs:Depends}, libgroonga (= ${binary:Version})
Description: Development files to use groonga as a library
Groonga is an open-source fulltext search engine and column store.
It lets you write high-performance applications that requires fulltext search.
.
This package provides header files to use groonga as a library.
それぞれ以下のような意味です。
- Package
- パッケージ名
- Section
- パッケージが属するセクション。Debian公式のセクションはDebianポリシーマニュアル - 2.4 セクションにある。libgroongaは「lib」、libgroonga-devは「libdevel」、groongaは「database」に属することにする。
- Architecture
- ビルド可能なマシンアーキテクチャ。スクリプト言語のソースなどアーキテクチャに依存しない場合は「all」を指定する。どのアーキテクチャでもビルドできるときは「any」を指定する。
- Depends
-
依存しているパッケージ。「${misc:Depends}」、「${shlibs:Depends}」はビルドされたファイルから自動的に検出された依存パッケージに置換される。/usr/bin/dh_*を見ると、他にも「${python:Depends}」などがあるよう。
「libgroonga (= ${binary:Version})」とバージョン指定付きで明示的にlibgroongaを指定しているのは、異なるバージョンのgroongaパッケージを使用しないようにするため。同じソースから生成したパッケージではバージョンまで指定しておく方が無難。
- Description
- パッケージの説明。1行目は短い説明を書き、2行目以降により詳細な説明を書く。2行目以降は先頭に1文字空白を入れることに注意。「.」だけの行は空行になる。
libgroonga, groongaパッケージも含んだdebian/controlは以下のようになります。それぞれのパッケージについての記述は空行で区切ります。
Source: groonga
Priority: optional
Maintainer: Kouhei Sutou <kou@clear-code.com>
Build-Depends: debhelper (>= 5), cdbs, autotools-dev, libmecab-dev
Standards-Version: 3.7.3
Homepage: http://groonga.org/
Package: libgroonga-dev
Section: libdevel
Architecture: any
Depends: ${misc:Depends}, ${shlibs:Depends}, libgroonga (= ${binary:Version})
Description: Development files to use groonga as a library
Groonga is an open-source fulltext search engine and column store.
It lets you write high-performance applications that requires fulltext search.
.
This package provides header files to use groonga as a library.
Package: libgroonga
Section: libs
Architecture: any
Depends: ${misc:Depends}, ${shlibs:Depends}
Description: Library files for groonga.
Groonga is an open-source fulltext search engine and column store.
It lets you write high-performance applications that requires fulltext search.
.
This package provides library files.
Package: groonga
Section: database
Architecture: any
Depends: ${misc:Depends}, ${shlibs:Depends}, libgroonga (= ${binary:Version})
Description: An open-source fulltext search engine and column store.
It lets you write high-performance applications that requires fulltext search.
.
This package provides 'groonga' command.
debian/rules
debian/rulesにはパッケージの作り方を書きます。CDBS(Common Debian Build System)を使うとよくある処理をより簡潔に書くことができます。
groongaはAutotoolsを使っているのでCDBSのAutotools用のファイルを読み込みます。
1 2 3 4 |
#!/usr/bin/make -f include /usr/share/cdbs/1/rules/debhelper.mk include /usr/share/cdbs/1/class/autotools.mk |
最初の行をみるとわかる通り、debian/rulesはMakefileと同じ書式を使います。
続いて、各パッケージで作成するディレクトリを指定します。変数の名前は「DEB_INSTALL_DIRS_#{パッケージ名}」となります。
1 2 3 4 5 6 7 8 9 10 |
DEB_INSTALL_DIRS_groonga = \
/usr/bin \
/usr/share/groonga
DEB_INSTALL_DIRS_libgroonga = \
/usr/lib
DEB_INSTALL_DIRS_libgroonga-dev = \
/usr/include/groonga \
/usr/lib/pkgconfig
|
groongaパッケージでは/usr/bin/groongaをインストールするので、/usr/binを指定する、libgroonga-devパッケージでは/usr/include/groonga/groonga.hをインストールするので/usr/include/groongaを指定するといった具合です。
最後にそれぞれのパッケージにどのファイルを含めるかを指定します。ターゲットの名前は「install/#{パッケージ名}」となります。ターゲットの後の「:」がふたつなのは実行する処理を追加しているためです。GNU makeの「::」の挙動について詳しく知りたい場合はGNU makeのinfoのDouble-Colon Rulesのところを読んでください。
1 2 3 4 5 6 7 8 9 10 11 12 13 |
install/groonga::
cp -ar debian/tmp/usr/bin/* debian/groonga/usr/bin/
cp -ar debian/tmp/usr/share/groonga/* \
debian/groonga/usr/share/groonga/
install/libgroonga::
cp -ar debian/tmp/usr/lib/libgroonga* debian/libgroonga/usr/lib/
install/libgroonga-dev::
cp -ar debian/tmp/usr/include/groonga/* \
debian/libgroonga-dev/usr/include/groonga/
cp -ar debian/tmp/usr/lib/pkgconfig/* \
debian/libgroonga-dev/usr/lib/pkgconfig/
|
ビルドしたファイルはdebian/tmp/以下にインストールされます。インストールされたファイルをcpでそれぞれのパッケージに振り分けています。通常はdh_movefilesを使うようなのですがinstall/libgroongaで使っているようなワイルドカードが使えないようなのでcpを使っています。
debian/rules全体はこうなります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
#!/usr/bin/make -f
include /usr/share/cdbs/1/rules/debhelper.mk
include /usr/share/cdbs/1/class/autotools.mk
DEB_INSTALL_DIRS_groonga = \
/usr/bin \
/usr/share/groonga
DEB_INSTALL_DIRS_libgroonga = \
/usr/lib
DEB_INSTALL_DIRS_libgroonga-dev = \
/usr/include/groonga \
/usr/lib/pkgconfig
install/groonga::
cp -ar debian/tmp/usr/bin/* debian/groonga/usr/bin/
cp -ar debian/tmp/usr/share/groonga/* \
debian/groonga/usr/share/groonga/
install/libgroonga::
cp -ar debian/tmp/usr/lib/libgroonga* debian/libgroonga/usr/lib/
install/libgroonga-dev::
cp -ar debian/tmp/usr/include/groonga/* \
debian/libgroonga-dev/usr/include/groonga/
cp -ar debian/tmp/usr/lib/pkgconfig/* \
debian/libgroonga-dev/usr/lib/pkgconfig/
|
debian/copyright
debian/copyrightにはソースの作者・ライセンスとパッケージの作者・ライセンス情報を書きます。ソースの作者・ライセンス情報はソースの中にある情報を利用します。groongaの場合はAUTHORSファイルに作者がリストされていました。著作権者の情報はソースのヘッダーファイルに、ライセンスの情報はCOPYINGにありました。
パッケージのライセンスはGPLv3+にしました。
This package was debianized by Kouhei Sutou <kou@clear-code.com> on
Thu, 15 Jan 2010 14:52:04 +0000.
It was downloaded from <http://groonga.org/>
Upstream Author(s):
Daijiro MORI <morita at razil. jp>
Tasuku SUENAGA <a at razil. jp>
Yutaro Shimamura <yu at razil. jp>
Kouhei Sutou <kou at cozmixng. org>
Kazuho Oku <kazuhooku at gmail. com>
Moriyoshi Koizumi <moriyoshi at gmail. com>
Copyright:
Copyright(C) 2009-2010 Brazil
License:
This library is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as published by
the Free Software Foundation, either version 2.1 of the License.
This library is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
The Debian packaging is (C) 2010, Kouhei Sutou <kou@clear-code.com> and
is licensed under the GPL, see `/usr/share/common-licenses/GPL'.
# Please also look if there are files or directories which have a
# different copyright/license attached and list them here.
debian/changelog
debian/changelogには変更履歴を書きます。パッケージのバージョンはこのファイルから抽出されるのでパッケージのバージョンを上げた場合はこのファイルに追記することを忘れてはいけません。
debian/changelogに変更履歴を追記するための専用のコマンドdchがあるので、それを利用します。-vオプションで新しいバージョンを指定します。
% dch -v 0.1.5
例えば、以下のように書きます。
groonga (0.1.5) unstable; urgency=low * New upstream release -- Kouhei Sutou <kou@clear-code.com> Mon, 18 Jan 2010 17:58:31 +0900
これでパッケージに必要な情報はできあがりました。
パッケージのビルド
パッケージをビルドするにはソースディレクトリで以下のコマンドを実行します。
[groonga-0.1.5]% debuild -us -uc
-usは.dscファイルにGPGでサインしないオプションで、-ucは.changesファイルにGPGでサインしないオプションです。
パッケージ作成を試行錯誤しているときは毎回ソースをビルドするのは面倒なものです。そのときは以下のように-ncオプションを指定すると、ビルド前にmake cleanを実行しなくなるのでビルドしなおさなくなります。
[groonga-0.1.5]% debuild -us -uc -nc
パッケージの作成が成功するとトップディレクトリにパッケージが作成されます。
. |--- groonga-0.1.5/ | |--- debian/ | | |... | |... | ... |--- groonga_0.1.5.orig.tar.gz |--- groonga_0.1.5.diff.gz |--- groonga_0.1.5.dsc |--- groonga_0.1.5_amd64.build |--- groonga_0.1.5_amd64.changes |--- groonga_0.1.5_amd64.deb |--- libgroonga-dev_0.1.5_amd64.deb +--- libgroonga_0.1.5_amd64.deb
生成したパッケージはdpkgでインストールできます。
[groonga-0.1.5]% sudo dpkg -i ../*groonga*.deb
aptitude用に公開する方法
Debianパッケージを作るとインストールが楽になりますが、dpkgでインストールしている場合は依存関係を自動的に解決してくれません。依存関係を自動的に解決するためにはAPTリポジトリを作る必要があります。
ただし、用意するのはわりと面倒です。1つのDebian/Ubuntuのバージョン・アーキテクチャ向けであればまだ頑張ろうかという気にはなれますが、複数のバージョン・アーキテクチャをサポートする場合は嫌になることでしょう。
ここでは、Cutterやmilter managerで使用しているDebianパッケージ作成からAPTリポジトリの更新を自動化しているスクリプトを紹介します。これらのスクリプトはCutterのリポジトリ などで公開されています。環境依存の部分があるので、利用する場合は自分の環境用に変更して利用してください。ライセンスはGPLv3+としますので、ライセンスの範囲内で自由に利用してください。
ただし、以下の説明はかなりざっくりとしているので気になる方は自分でスクリプトをみてください。
Debianパッケージ作成の自動化
複数のバージョン・アーキテクチャをサポートする場合、それぞれの環境ごとのDebianパッケージを作成することが大変です。ここで紹介するスクリプトではDebian GNU/Linux sid (x86_64)の環境にchroot環境を作って、すべて同じマシン上で作成します。複数のマシンで作成してもよいのですが、そうするとOSのインストールやsshの設定などが面倒になります。
pbuilderを使うことも多いようですが、その環境の中にシェルで入って確認したいこともあるので、常にchroot環境を持っていた方が便利です*2。
Cutterの場合はchroot環境内で以下のビルドスクリプトを実行しています。単純なコマンドの羅列なので説明は省略します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
#!/bin/sh
VERSION=1.1.0
sudo aptitude -V -D update && sudo aptitude -V -D -y safe-upgrade
sudo aptitude install -y subversion devscripts debhelper cdbs autotools-dev \
intltool gtk-doc-tools libgtk2.0-dev libgoffice-0-{6,8}-dev \
libgstreamer0.10-dev libsoup2.4-dev
mkdir -p ~/work/c
if [ -d ~/work/c/cutter ]; then
cd ~/work/c/cutter
svn up
else
cd ~/work/c
svn co https://cutter.svn.sourceforge.net/svnroot/cutter/cutter/trunk cutter
fi
cd ~/work/c
rm -rf cutter-${VERSION}
tar xfz cutter_${VERSION}.orig.tar.gz
cd cutter-${VERSION}
mkdir debian
cp -rp ../cutter/debian/* debian/
if dpkg -l libgoffice-0-8-dev > /dev/null 2>&1; then
:
else
sed -i'' -e 's/libgoffice-0-8/libgoffice-0-6/g' debian/control
fi
debuild -us -uc
|
そして、このビルドスクリプトを各chroot環境内で実行するために以下のようなMakefileを使っています。Debian GNU/Linuxのlennyとsid、UbuntuのHardyとKarmicのパッケージを作成します。また、それぞれi386用とamd64用を生成するので8種類のパッケージを作成することになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
VERSION = 1.1.0
SERVER_PATH = ktou,cutter@web.sourceforge.net:/home/groups/c/cu/cutter/htdocs
DISTRIBUTIONS = debian ubuntu
CHROOT_BASE = /var/lib/chroot
ARCHITECTURES = i386 amd64
CODES = lenny unstable hardy karmic
update:
for code_name in $(CODES); do \
target=$${code_name}-$${architecture}; \
case $${code_name} in \
lenny|unstable) \
distribution=debian; \
section=main; \
;; \
*) \
distribution=ubuntu; \
section=main; \
;; \
esac; \
(cd $${distribution}; \
mkdir -p dists/$${code_name}/$${section}/source; \
for architecture in $(ARCHITECTURES); do \
mkdir -p dists/$${code_name}/$${section}/binary-$${architecture}; \
done; \
apt-ftparchive generate generate-$${code_name}.conf; \
rm -f dists/$${code_name}/Release*; \
apt-ftparchive -c release-$${code_name}.conf \
release dists/$${code_name} > /tmp/Release; \
mv /tmp/Release dists/$${code_name}; \
gpg --sign -ba -o dists/$${code_name}/Release{.gpg,}; \
); \
done
upload: update
for distribution in $(DISTRIBUTIONS); do \
(cd $${distribution}; \
rsync -avz --exclude .svn --delete \
dists pool $(SERVER_PATH)/$${distribution}; \
); \
done
download:
for distribution in $(DISTRIBUTIONS); do \
(cd $${distribution}; \
rsync -avz $(SERVER_PATH)/$${distribution}/pool/ pool; \
); \
done
build:
for architecture in $(ARCHITECTURES); do \
for code_name in $(CODES); do \
target=$${code_name}-$${architecture}; \
case $${code_name} in \
lenny|unstable) \
distribution=debian; \
section=main; \
;; \
*) \
distribution=ubuntu; \
section=main; \
;; \
esac; \
build_dir=$(CHROOT_BASE)/$$target/home/$$USER/work/c; \
pool_dir=$$distribution/pool/$$code_name/$$section/c/cutter; \
mkdir -p $$build_dir; \
cp ../cutter-$(VERSION).tar.gz \
$$build_dir/cutter_$(VERSION).orig.tar.gz && \
sudo su -c \
"chroot $(CHROOT_BASE)/$$target su - $$USER" < build-deb.sh; \
mkdir -p $$pool_dir; \
cp -p $$build_dir/*cutter*_$(VERSION)* $$pool_dir; \
done; \
done
|
細かい内容は省略しますが、以下のように使用します。準備が大変です。
% sudo mkdir -p /var/lib/chroot/ % sudo su -c 'debootstrap --arch i386 lenny /var/lib/chroot/lenny-i386' % sudo su -c 'debootstrap --arch amd64 lenny /var/lib/chroot/lenny-amd64' % sudo su -c 'debootstrap --arch i386 sid /var/lib/chroot/sid-i386' % sudo su -c 'debootstrap --arch amd64 sid /var/lib/chroot/sid-amd64' % sudo su -c 'debootstrap --arch i386 hardy /var/lib/chroot/hardy-i386' % sudo su -c 'debootstrap --arch amd64 hardy /var/lib/chroot/hardy-amd64' % sudo su -c 'debootstrap --arch i386 karmic /var/lib/chroot/karmic-i386' % sudo su -c 'debootstrap --arch amd64 karmic /var/lib/chroot/karmic-amd64' % sudo vim /etc/fstab proc /var/lib/chroot/lenny-i386/proc proc defaults 0 0 devpts /var/lib/chroot/lenny-i386/dev/pts devpts defaults 0 0 sysfs /var/lib/chroot/lenny-i386/sys sysfs defaults 0 0 ... % sudo mount -a ...それぞれのchroot環境に入って作業用ユーザを作成し、sudo可能にする...
準備ができたら以下のコマンドでパッケージがビルドできます。
% cd /tmp % svn export https://cutter.svn.sourceforge.net/svnroot/cutter/cutter/trunk/apt % wget http://downloads.sourceforge.net/cutter/cutter-1.1.0.tar.gz % cd apt % make build
成功すると*/pool/*/main/c/cutter/以下に.debが生成されています。
% ls */pool/*/main/c/cutter/*.deb debian/pool/lenny/main/c/cutter/cutter-bin_1.1.0-1_i386.deb debian/pool/lenny/main/c/cutter/cutter-doc_1.1.0-1_i386.deb ...
この状態でAPTリポジトリを作成できます。
% make update
GPGでサインしようとするのであらかじめGPGの設定を行っておいてください。APTリポジトリの作成に関する設定はdebian/*.confとubuntu/*.confです。環境に合わせて変更してください。
Makefileの中にはuploadというターゲットがあります。このターゲットを使うとupdateで作成したAPTリポジトリをsf.netのWebサーバにrsyncでアップロードできます。
まとめ
groongaを例にしてDebianパッケージの作成方法を説明しました。ついでに、APTリポジトリの公開方法もざっくりと紹介しました。
Debianパッケージの作り方やAPTリポジトリの公開方法は、必要な人はあまりいないかもしれませんが、groongaのDebianパッケージを必要としている人はそれよりもいそうな気がします。もしよかったら使ってみてください。
この記事の続き
告知: LOCAL DEVELOPER DAY '10/Winter: メールフィルタの作り方 - Rubyで作るmilter
来月2/13(土)に札幌で開催されるLOCAL DEVELOPER DAY '10/WinterでRubyでメールフィルターを作る方法について話します。
- 日時
- 2010/2/13(土) 12:45〜18:35
- 場所
- 札幌市産業振興センター セミナールームA
- 参加費用
- 無料
- 参加登録
- 必要無し(懇親会は登録が必要)
内容
Rubyでメールフィルターを開発する方法について話します。以下、背景などをまじえてもう少し詳しく説明します。
SendmailやPostfixといったよく使われているメールサーバにはmilterというメールフィルターを追加する仕組みが実装されています。milterを使うことにより、メールサーバに迷惑メール対策機能やウィルスチェック機能、メールアーカイブ機能、添付ファイル自動暗号化機能などを追加することができます。つまり、メールサーバ本体を変更せずに組織のポリシーに合わせたメールシステムを構築することができるということです。
milterという仕組みを使ったメールフィルター*1はすでにたくさん開発されているので、既存のものを組み合わせてメールシステムを構築できることも多いです。しかし、組織特有の事情などがある場合は既存のメールフィルターでは対応できないこともあるでしょう。そういった場合、新しくメールフィルターを開発したり既存のメールフィルターを改造して対応できます。
通常、メールフィルターはC言語で開発する必要がありますが、milter maangerが提供する機能を利用することによってRubyを使って素早くメールフィルターを開発することができます。
今回は、milter managerの機能を使ってRubyでメールフィルターを開発する方法やデバッグの方法などを紹介します。milterという仕組みを知らない方でもわかるように、milterという仕組みから順を追って説明します。ただし、Rubyについて詳しく説明しないので、Rubyがまったくわからない方には少し厳しいかもしれません。札幌でRubyについて詳しくなりたい方はRuby札幌に参加することをオススメします。
まとめ
来月開催されるLOCAL DEVELOPER DAY '10/Winterで、Rubyを用いてメールフィルターを作る方法について話すので、それを告知しました。
JavaScript(Ext JS)やWebアプリケーションのテスト(Selenium)、ドキュメント指向データベース(MongoDB)、リレーショナルデータベース(PostgreSQL)の話などもあるようです。参加登録も必要ないので、興味のある方はお気軽に参加してみてはいかがでしょうか。
*1 混乱するかもしれませんが、「milterという仕組みを使ったメールフィルター」もmilterと呼びます。milterといった場合は仕組みよりメールフィルターのことを指すことが多いです。
処理待ちをより簡単に行えるようになったUxU 0.7.6をリリースしました
2010年1月29日付で、テスティングフレームワークUxUのバージョン0.7.6をリリースしました。
新機能のutils.wait()について
今回のアップデートでの目玉となる新機能は、非同期な機能のテストをより簡単に記述できるようにするヘルパーメソッドであるutils.wait()です。これは、以下のように利用します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
function testSendRequest() { myFeature.sendRequest(); utils.wait(1000); // 1000ミリ秒=1秒待つ assert.equals('OK', myFeature.response); } function testLoad() { var loaded = { value : false }; content.addEventListener('load', function() { content.removeEventListener('load', arguments.callee, false); loaded.valeu = true; }, false); myFeature.load(); utils.wait(loaded); // valueがtrueになるまで待つ assert.equals('OK', content.document.body.textContent); } |
また、utils.wait()は関数の中でも利用できます。
1 2 3 4 5 6 7 8 9 10 |
function testSendRequest() { function assertSend(aExpected, aURI) { myFeature.sendRequest(aURI); utils.wait(1000); assert.equals(aExpected, myFeature.response); } assertSend('OK', '...'); assertSend('NG', '...'); assertSend('?', '...'); } |
utils.wait()が受け取れる値は、これまでの処理待ち機能で yieldに渡されていた値と同じです。詳しくは処理待ち機能の利用方法をご覧下さい。大抵の場合、yield Do(...);と書かれていた箇所は、utils.wait(...);へ書き換えることができます。
ただし、このヘルパーメソッドはFirefox 3以降やThunderbird 3以降など、Gecko 1.9系の環境でしか利用できません。Thunderbird 2などのGecko 1.8系の環境ではエラーとなりますのでご注意下さい。(それらの環境でもテストの中で処理待ちを行いたい場合は、従来通りyieldを使用して下さい。)
これまでの処理待ち機能の特徴と欠点
これまでUxUでは、「機能を実行した後、N秒間待ってから、機能が期待通りに働いたかどうかを検証する」「初期化処理で、ページの読み込みの完了を待ってから次に進む」といった処理待ちを実現する際は、JavaScript 1.7以降で導入されたyieldを使う仕様となっていました。
yieldを含む関数はジェネレータとなり、関数の戻り値をイテレータとして利用できるようになります。この時ジェネレータの内側から見ると、「yieldが出現する度に処理が一時停止する」という風に考えることができます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
function gen() { alert('step1'); yield 'step1 done'; alert('step2'); yield 'step2 done'; alert('step3'); } var iterator = gen(); // この時点ではまだ関数の内容は評価されない var state; state = iterator.next(); // 'step1' が表示される alert(state); // 'step1 done' が表示される state = iterator.next(); // 'step2' が表示される alert(state); // 'step2 done' が表示される try { state = iterator.next(); // alert('step3'); が実行される } catch(e if e instanceof StopIteration) { // 次のyieldが見つからないので、StopIteration例外が投げられる } |
UxUに従来からある処理待ち機能は、この考え方を推し進めて作られています。テスト関数の中にyieldがある場合(つまり、関数の戻り値がイテレータとなる場合)は、フレームワーク側で自動的にイテレーションを行い、yieldに渡された値をその都度受け取って、次にイテレーションを行うまでの待ち条件として利用しています。例えば、数値が渡された場合はその値の分の時間だけ待った後で次にイテレーションを行う、といった具合です。
このやり方の欠点は、yieldを含む関数から任意の戻り値を返すことができないという点です。
1 2 3 4 5 6 7 8 9 10 11 |
function gen() { alert('step1'); yield 'step1 done'; alert('step2'); return 'complete'; } try { var iterator = gen(); } catch(e) { alert(e); // TypeError: generator function gen returns a value } |
returnを書くと、関数の実行時にエラーになってしまいます。どうしても何らかの値を取り出したい場合は、値を取り出すためのスロットとなるオブジェクトを引数として渡すなどの工夫が必要になります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
function gen(aResult) { alert('step1'); yield 'step1 done'; alert('step2'); aResult.value = 'complete'; } var result = {}; var iterator = gen(result); var state; state = iterator.next(); // 'step1' が表示される alert(state); // 'step1 done' が表示される try { state = iterator.next(); // 'step2' が表示される } catch(e if e instanceof StopIteration) { alert(result.value); // 'complete' が表示される } |
また、ジェネレータは実行してもその段階では関数の内容が評価されないという点にも注意が必要です。例えば以下のようなテストは、期待通りには動いてくれません。
1 2 3 4 5 6 7 8 9 10 |
function testSendRequest() { function assertSend(aExpected, aURI) { myFeature.sendRequest(aURI); yield 1000; assert.equals(aExpected, myFeature.response); } assertSend('OK', '...'); assertSend('NG', '...'); assertSend('?', '...'); } |
この例では、assertSend()を実行したことで戻り値としてイテレータが返されているものの、そのイテレータに対するイテレーションが一切行われていないため、リクエストも行われなければアサーションも行われないということになってしまっています。これは以下のように、返されたイテレータをそのままフレームワークに引き渡して、フレームワーク側でイテレーションを行わせる必要があります。
1 2 3 4 5 6 7 8 9 10 |
function testSendRequest() { function assertSend(aExpected, aURI) { myFeature.sendRequest(aURI); yield 1000; assert.equals(aExpected, myFeature.response); } yield assertSend('OK', '...'); yield assertSend('NG', '...'); yield assertSend('?', '...'); } |
また、このままではジェネレータの中で発生した例外のスタックトレースを辿れないという問題もあります。スタックを繋げるためには、ヘルパーメソッドのDo()を使ってyield Do( assertSend('OK', '...') )のように書かなければなりません。
utils.wait()を使う場合、これらのことを考慮する必要はありません。冒頭のサンプルコードのように、素直に書けば素直に動作してくれます。
スレッド機能を使った処理待ち
utils.wait()がどのように実装されているかについても解説しておきます。
このメソッドの内部では、Gecko 1.9から実装されたスレッド関連の機能を利用しています。
1 2 3 4 |
window.setTimeout(function() { alert('before'); }, 0); alert('after'); |
JavaScriptは基本的にシングルスレッドで動作するため、このようにタイマーを設定すると、その処理はキューに溜められた状態となります。その上で、メインの処理が最後まで終わった後でやっとキューの内容が処理され始めるため、この例であれば「after」「before」の順でメッセージが表示されることになります。
1 2 3 4 5 6 7 8 9 10 11 12 |
var finished = false; window.setTimeout(function() { alert('before'); finished = true; }, 0); var thread = Cc['@mozilla.org/thread-manager;1'] .getService() .mainThread; while (!finished) { thread.processNextEvent(true); } alert('after'); |
Gecko 1.9以降のスレッド機能を使うと、メインの処理を一旦中断して先にキューに溜められた処理の方を実行し、その後改めてメインの処理に戻るということができます。実際に、こちらの例では「before」「after」の順でメッセージが表示されます。UxU 0.7.6ではこれを応用して、任意の条件が満たされるまでthread.processNextEvent(true);でメインの処理を停止し続けることによって、処理待ちを実現しています。
なお、HTML5にもWeb Workersというスレッド関係の機能がありますが、こちらは別スレッドでスクリプトを動作させる機能しか持っていないため、上記のようなことは残念ながらできません。
まとめ
UxU 0.7.6からは、utils.wait()を使ってより簡単に処理待ちを行えるようになりました。Firefox 3以降やThunderbird 3以降専用にアドオンを開発する際には、是非利用してみて下さい。
この記事の続き
- ククログの記事はCC BY-SA 4.0とGFDLのデュアルライセンスで自由に利用できます。
- クリアコードはプログラミングが楽しいソフトウェア開発者を1名募集しています。
- クリアコードは「クリアコードをいい感じにする人」を1名募集しています。
- クリアコードはフリーソフトウェア開発で培った技術力を提供しています。特にMozilla製品(Mozilla FirefoxとMozilla Thunderbird)とRubyとGroonga(全文検索)に関連した開発を得意としています。