ククログ
Fluentdのベンチマークツールの開発
はじめに
クリアコードはFluentdの開発に参加しています。
Fluentdにはプラグインというしくみがあり、たくさんのプラグインが開発されています。
Fluentdのプラグインでは各種APIを使用しており、プラグインによって消費するリソースの傾向が異なるということがあります。
今回そのリソースの傾向はどの程度なのかを知るために筆者畑ケがベンチマークツールを開発し、傾向を測定しました。
Windows EventLogを扱うプラグイン
Windows EventLogを引っ張ってくるプラグインは https://github.com/fluent/fluent-plugin-windows-eventlog にて開発されています。Fluentdの開発チームはwin32-eventlog gemでは対処しきれないEventLogの形式があることから、winevt_c gemを開発しています。
このgemは基本的にCで書かれているため、大きなボトルネックになることはありませんが、リソースの消費傾向を把握するのは重要と考えています。
Fluentdのベンチマークの考え方
FluentdのInputプラグインやOutputプラグインは基本的にある間隔で動作します。また、Outputプラグインはすぐに送ることはせずにbufferingをします。このことから、Fluentdが消費しているリソースを時間ごとにモニタリングした生データを単にプロットするだけではどの程度のリソース消費をするかが判りにくくなります。
リソースの消費傾向は中央値(メジアン)・25パーセンタイル〜75パーセンタイルの範囲、そして99パーセンタイル程度の測定値がどの程度の範囲内にあるかを図示した方がリソースの消費傾向が分かりやすくなります。
箱ヒゲ図(Box Plot)とは
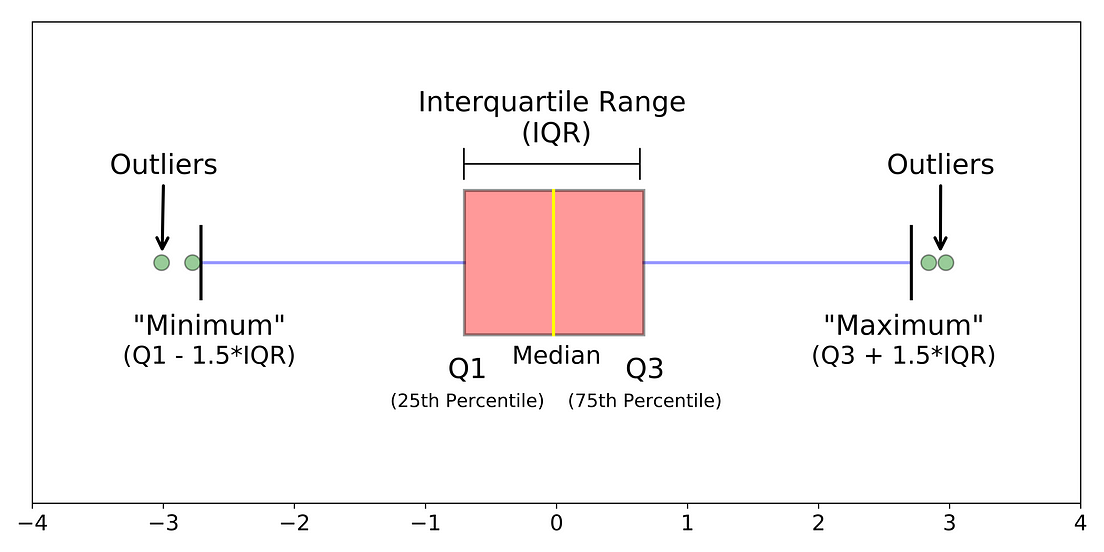
箱ヒゲ図とは、データのばらつきを分かりやすく表現するためのグラフの一種です。 例として以下の図にあるような箱ヒゲ図を見てみます。
(https://towardsdatascience.com/understanding-boxplots-5e2df7bcbd51 より引用)
この箱ヒゲ図では、真ん中の箱の範囲に25パーセンタイルから75パーセンタイルの中位50パーセンタイルの数値が入ります。
また、下ヒゲから箱の下までが下位24.65パーセンタイル、上ヒゲから箱の上までが上位24.65パーセンタイルの数値が入ります。下ヒゲから上ヒゲまでが99.3パーセンタイルの数値が入ります。時折生じるリソース消費のスパイク現象を除いたリソースの消費量を見るには、下ヒゲから上ヒゲの99.3パーセンタイルの範囲の数値をみると良いことになります。
この箱ヒゲ図を正規分布に対応させると以下のようになります。

(https://towardsdatascience.com/understanding-boxplots-5e2df7bcbd51 より引用)
ただし、この箱ヒゲ図には重要な仮定があります。値の分布が正規分布*1 に従っている*2という条件があります。
ベンチマーク環境の作成
こちらはTerraformを用いてAzureにベンチマーク環境を整えることで実施しました。
また、ベンチマーク後のグラフの描画にはmatplotlibを基にしたseabornを用いています。
Windows EventLogのベンチマークを実施する
ベンチマークの準備
まず、Python3の環境をセットアップします。ベンチマーク環境を整備するにはpython3のインストールが必要です。
ここでは、ホスト環境がUbuntuであると仮定します。
$ sudo apt install python3 python3-venv build-essentials
ベンチマーク環境をセットアップするスクリプトをgit cloneします。
$ git clone https://github.com/fluent-plugins-nursery/fluentd-benchmark-azure-environment.git
$ cd fluentd-benchmark-azure-environment
venvを使ってシステムのPython3環境と分離します。
$ python3 -m venv management
$ source management/bin/activate
requirements.txtを使って必要なPython3のライブラリをインストールします。
$ pip3 install -r requrirements.txt
Ubuntuで実行可能なTerraformを https://www.terraform.io/downloads.html からダウンロードして来てインストールします。
この記事ではWindows EventLogのベンチマークの実行を例にするため、winevtlog_benchディレクトリにcdします。
$ cd winevtlog_bench
Terraformを初期化して、必要なProviderをダウンロードします。
$ terraform init
terraform.tfvars.sampleをコピーします。
$ cp terraform.tfvars.sample terraform.tfvars
以下の変数の値を実際に使用するものに書き換えます。
linux-username = "admin"
linux-password = "changeme!"
region = "Japan East"
windows-username = "admin"
windows-password = "changeme"
ssh-private-key-path = "/path/to/private_key"
resource-group = "ExampleGroup"
ssh-keygenを用いてid_rsa_azureというRSA 2048ビットの秘密鍵と公開鍵を生成します。id_rsa_azure.pubを、azure_keyというディレクトリに格納します。
Azureの認証情報は Terraformの導入 - 検証環境をコマンドで立ち上げられるようにする その1 を参考に取得します。
env.shをコピーし、
$ cp env.sh.sample env.sh
#!/bin/sh
echo "Setting environment variables for Terraform"
export ARM_SUBSCRIPTION_ID=<SUBSCRIPTION_ID>
export ARM_CLIENT_ID=<APP_ID>
export ARM_CLIENT_SECRET=<APP_PASSWORD>
export ARM_TENANT_ID=<TENANT_ID>
スクリプト中の角かっこの値を埋めて、env.shを読み込みます。
$ source env.sh
また、AzureのCLIでのログインは事前に行っておいてください。
ここまででTerraformを使ったベンチマーク用のAzureインスタンスを建てる準備が整いました。
ベンチマークの実施
ベンチマークの実施方法はMakefileとAnsible Playbookに集約されているので順番に実行していけば良いです。
$ make apply
により、Azure上にベンチマーク用のインスタンスが建ちます。
$ make provision
により、ベンチマークに必要なライブラリやツールが建てたAzureのインスタンスにダウンロードされ、インストールされます。
Windows EventLogの単純なベンチマークは、
$ make windows-bench
により実施されます。このコマンドを実行すると、裏ではAnsible Playbook化されたタスクが走ります。
このタスクはWindows上で採取されたデータを収集する部分まで含まれます。
ベンチマーク結果の可視化には次のコマンドも実行します。
$ make visualize
このコマンドにより、ベンチマーク結果を箱ヒゲ図で可視化できます。
ベンチマークが終わった後は、ベンチマークに使ったAzureインスタンスを破棄してしまいましょう。
$ make clean
ベンチマーク結果の一例
CPUの消費傾向を箱ヒゲ図で見てみます。
また、記事中では解説していませんが、外れ値があるかどうかもチェックしたいため、strip plotで実際の値も箱ヒゲ図に重ねてプロットしています。小数点以下第3位で四捨五入したメジアンの値ラベルについても、箱ヒゲ図に重ねてプロットしています。
およそ12分で120000イベントのWindows EventLogをin_windows_eventlog2で受け取った場合のFluentdのワーカーのCPU使用率です。
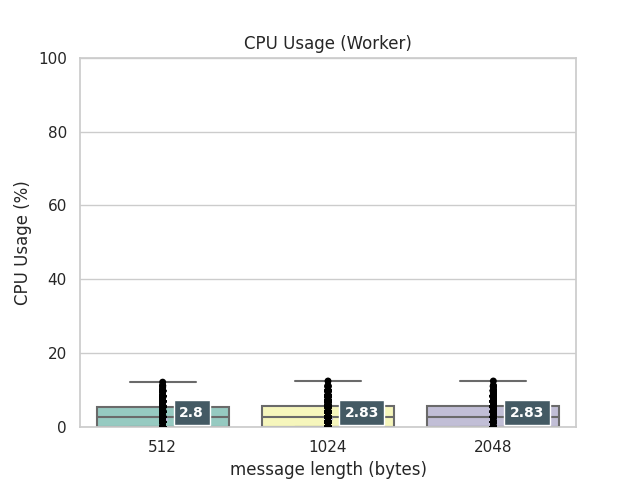
おおよそ1分間に159イベント程度を決められたチャンネルに書き込む流量があります。
このベンチマークでは、イベントの流量とサイズが大きくないため、ワーカープロセスのCPU使用率には差が出ていません。
ワーカープロセスのメモリ使用量はどうでしょうか。
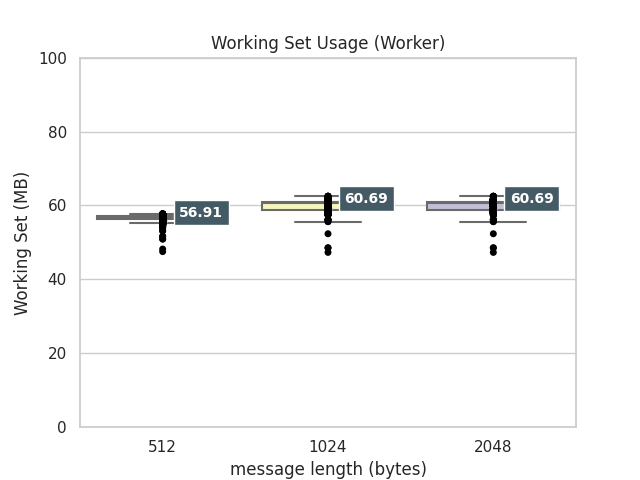
こちらは、受け取ったメッセージサイズに多少影響を受けるところが見て取れます。
まとめ
Fluentdのプラグインのベンチマークの方法を解説してみました。
Windows向けに開発したプラグインでは、Linux向けとは違うリソースを消費する傾向になってしまう事があります。
Windows EventLogを扱う際にはWindowsが提供するAPI経由となるため、Cで書いている箇所に関しては大幅なボトルネックとなってしまう箇所が少ない事が確認できました。
また、ある程度の流量にも耐えられうる状態で提供できていることも確認できました。
ノータブルコード10 - 文芸的設定ファイル
第10回目のノータブルコードで紹介するのは、ドナルド・クヌースの設定ファイルです。
文芸的プログラミングとは何か
ドナルド・クヌースは『The Art of Computer Programming』の作者、そして組版ソフトウェアTeXの開発者として世界的に名を知られた伝説的な人物ですが、彼はまた「文芸的プログラミング」の概念を提唱したことでも知られています。今日の記事のテーマは、彼の業績のうちの文芸的プログラミングに関する部分です。
文芸的プログラミングの哲学を、一言で説明するのは難しいのですが、その基本的な発想は、プログラムを、単に機械が解釈できるフォーマルな命令の羅列ではなく、人間が読むことができる自然な文章としても提示しようというアイデアにありました(クヌース自身はこれを「自然言語である英語と、CやLispのような形式言語の間で切り替えをし、まとめ上げられる自然なフレームワーク」*1と表現しています)。 この哲学の実践的なメリットは、その原理が正しく実行されれば、真の意味で「人間が読むことのできるプログラム」を生み出せることです。
クヌースが真に偉大なのは言行一致であること、すなわち自分が提唱しているアイデアを、自ら実践しているところです — これが今日の記事の本題につながります。クヌースはTeXのような公開を意図したプログラムはもちろんのこと、個人的に書くプログラムでも文芸的なスタイルを採用していると語っています。
そして、そのスタイルの適用範囲は、驚くべきことに、設定ファイルにも及ぶのです。
クヌースの設定ファイル
実際の例を見てみましょう。以下に引用するのは、クヌース自身の手になるFVWM2向け設定ファイルの冒頭部分です。
https://www-cs-faculty.stanford.edu/~knuth/programs/.fvwm2rc
# This Fvwm2 setup file provides the basic emacs-centered environment
# that I have found most comfortable on my standalone machine at home.
# Basically it gives me a big Emacs window at the left and a slightly
# smaller XTerm at the right, together with a clock and CPU monitor
# and a few buttons for accessing independent desktops.
# I've tried to write lots of comments because I will certainly forget
# most of the details of Fvwm2's syntax and semantics before long.
# My display screen is 1440 pixels wide and 900 high.
# First, make sure that Exec chooses tcsh instead of bash:
ExecUseShell /bin/tcsh
# Next, specify the paths for all icons (.xpm files) that I'm using:
# PixmapPath /usr/share/icons:/home/icons
ImagePath /home/icons:/usr/share/icons
# I tried mxn desktops and didn't like them.
DeskTopSize 1x1
全文は274行あるので、ぜひリンク先も見てください。この記事では、次の3つのポイントを指摘しておきたいと思います。
-
まず、この設定ファイルはごく自然な文章として読むことができます。「文芸的」の名前に違わず、プログラム向けの設定と、人間向けの説明がごく自然に統合されています。
-
また、設定の背景にある前提は何かが明示されているのもポイントです。例えば、普段はEmacsとXTermを利用していること、設定の対象となるディスプレイが1440x900のサイズであること、などの背後にある隠れた重要な前提がきちんと読者に示されています。
-
さらに見逃せないポイントは、設定の構成自体が、自然言語の文章の流れに沿うように組み立てられている点です。これは、プログラムのいわば後付けとしてコメントを付与する一般的な流儀とは、明確に発想を異にしている点です。
もちろん、このスタイルをすべての人が実践できるか、というと議論があるところです。というのも、明らかにこの手法は (1) プログラマとしての能力に加えて (2) 優れた文章の書き手としての能力を兼ね備えていないと実践できないからです。
それでも、この設定ファイルが「ちょっと文芸的スタイルを試してみようかな」と読み手に関心を引かせるほどの魅力を持っているのは事実です。ともすると、プログラミングを数理科学の一つとして位置づける現在主流の考え方は根本的に間違っていて、本当は人文科学としての国語の一分野なのかもしれない、そう思わせるほどの説得力が、このコードにはあります。
まとめ
今日の記事では、文芸的プログラミングの実践例としての(文芸的)設定ファイルを紹介しました。
この設定ファイルを読んで、皆さんはどう思いましたか?ご意見ご感想があればぜひお寄せください。
*1 ピーター・サイベル著・青木靖訳「Coders at Work プログラミングの技をめぐる探求」(オーム社, 2011年)p558
gbpを使ったDebianパッケージでパッチのファイル名を明示的に指定するには
はじめに
Debianパッケージのメンテナンスではgbpコマンドがしばしば使われます。
gbpを使ったワークフローでは、従来やや面倒だったquiltを意識せずにパッチを管理できます。
ただし、特に指定をしなければコミットメッセージからファイル名が自動的に設定されてしまいます。*1
debian/patches以下にあるパッチのファイル名を明示的に指定するにはどうすればよいでしょうか。
gbp pqコマンドを利用したパッチ管理をする
gbpにはgbp pqというパッチ管理のためのコマンドがあります。
gbp pqを使うと、冒頭で述べたようにquiltを意識せずにパッチを管理できます。*2
仮にdebian/unstableブランチでunstable向けのパッケージをメンテンナンスをしているときに次のコマンドを実行すると、
パッチを管理するためのブランチをrebaseできます。
gbp pq rebase
rebase後のブランチ名はpatch-queue/debian/unstableです。
このブランチではdebian/unstableブランチにdebian/patches/以下のパッチがコミットされている状態となります。
Gbp-Pq:タグを使う
gbp-pq(1)を読むと書いてありますが、コミットメッセージにGbp-Pq:タグを含めます。
Gbp-Pq:タグを含んだコミットとは例えば次のようなコミットです。
commit 9f956f8232cce926eed52ab3fb2ed3f951d40652
Author: Steven Chamberlain <stevenc@debian.org>
AuthorDate: Sat Jul 16 23:52:50 2016 +0100
Commit: Kentaro Hayashi <kenhys@gmail.com>
CommitDate: Mon Jul 20 21:37:15 2020 +0900
Use _GNU_SOURCE on GNU/kFreeBSD
Define _GNU_SOURCE not only on GNU/Hurd, but also other glibc-based
platforms including GNU/kFreeBSD.
See https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=826061#10
Gbp-Pq: Name fix-nginx-FTBFS-on-kfreebsd.patch
---
vendor/nginx-1.17.9/src/os/unix/ngx_posix_config.h | 5 ++++-
1 file changed, 4 insertions(+), 1 deletion(-)
diff --git a/vendor/nginx-1.17.9/src/os/unix/ngx_posix_config.h b/vendor/nginx-1.17.9/src/os/unix/ngx_posix_config.h
index 2a8c413e..03f7e0a5 100644
--- a/vendor/nginx-1.17.9/src/os/unix/ngx_posix_config.h
+++ b/vendor/nginx-1.17.9/src/os/unix/ngx_posix_config.h
@@ -21,10 +21,13 @@
#endif
-#if (NGX_GNU_HURD)
+#if defined(__GLIBC__)
#ifndef _GNU_SOURCE
#define _GNU_SOURCE /* accept4() */
#endif
+#endif
+
+#if (NGX_GNU_HURD)
#define _FILE_OFFSET_BITS 64
#endif
この状態でgbp pq exportを実行すると、debian/patches/fix-nginx-FTBFS-on-kfreebsd.patchが生成されます。簡単ですね。
まとめ
今回は、gbpを使ったパッチ管理においてファイル名を明示的に指定する方法(Gbp-Pq: Name)を紹介しました。
patches以下にパッチを貯めるのはあまりおすすめできませんが、Debianパッケージをgbpでメンテナンスするときに必要になったら参考にしてみてください。
Fluentd-kubernetes-daemonsetのElasticsearchイメージでILMを使う
はじめに
クリアコードはFluentdの開発に参加しています。
Fluentdにはプラグインというしくみがあり、たくさんのプラグインが開発されています。
Fluentdはログ収集ソフトウェアということからkubernetes(以下k8sと略記)にも載せることができます。
Fluentdの開発元が公式に出しているk8sでのログ収集の仕組みの一つとしてFluentdのDaemonSetを提供しています。
筆者畑ケはElasticsearchのILM対応を最近fluent-plugin-elasticsearchに入れました。*1
筆者が対応したILMをFluentdのDaemonSetでも有効化して動かすことができたので、報告します。
ILMを有効化していると、古くなったインデックスを定期的に消すというオペレーションをElasticsearch自体に任せることができ、Elasticsearchのクラスターの管理の手間を減らせます。
k8sのkind
まず、Fluentdのログ収集を解説する前に、k8sに少し触れておきます。
この記事ではminikube v1.11.0、Kubernetes v1.18.3を想定しています。
k8sではいくつかのリソースの管理方法があります。リソースはオブジェクト毎に名前が付けられており、yamlでオブジェクトの振る舞いを決定します。
ここで、単純なコンテナをk8sにデプロイするには、例えば以下のようにnginxのDeploymentを作成します。
apiVersion: apps/v1
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
これを
$ kubectl apply -f ngix-deployment.yaml
deployment.apps/nginx-deployment created
とする事で、nginxのコンテナがk8s上で動作し始めます。
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-6b474476c4-vhtmn 1/1 Running 0 34s
nginx-deployment-6b474476c4-xqr4f 1/1 Running 0 34s
動作確認が終わったらDeploymentを片付けておきましょう。
$ kubectl delete deployment nginx-deployment
deployment.apps "nginx-deployment" deleted
k8sのDaemonSetとは
k8sにはDaemonSetというkindがあり、これはクラスターを構成するNode上にDaemonSetが構成するPodを自動的に配置するために使用されるkindです。
DaemonSetのこの性質を用いる事で、各Node上のログを集めるPodを自動的に配置するFluentdのDaemonSetが作成できます。
FluentdのDaemonSet
FluentdのDaemonsetは公式では https://github.com/fluent/fluentd-kubernetes-daemonset にて開発がされています。
執筆時点では以下のイメージがDaemonSet用に提供されています。
- debian-elasticsearch7
- debian-elasticsearch6
- debian-loggly
- debian-logentries
- debian-cloudwatch
- debian-stackdriver
- debian-s3
- debian-syslog
- debian-forward
- debian-gcs
- debian-graylog
- debian-papertrail
- debian-logzio
- debian-kafka
- debian-kinesis
この記事では、debian-elasticsearch7のdocker imageを参照しているfluentd-kubernetes-daemonsetの設定を元にして、ILMを有効化したロギング環境を構築します。
FluentdのElasticsearch7 Daemonset
Fluentdでログ収集をした後に、Elasticsearchを用いてログをストアするDaemonSetは例えば、 fluentd-daemonset-elasticsearch.yamlです。この設定ではRBACを使っていませんが、簡単のためこのDaemonSetをもとにして構成します。
また、この記事で使用するdebian-elasticsearchのimageのtagはfluent/fluentd-kubernetes-daemonset:v1.11.1-debian-elasticsearch7-1.3 または fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearchを用いています。
記事が公開されるタイミングではどちらのタグを使用しても大丈夫です。
元のDaemonSetの構成ではElasticsearchのテンプレート設定が入っていないため、テンプレートの設定をConfigMapで表現することにします。
apiVersion: v1
data:
index_template.json: |-
{
"index_patterns": [
"logstash-default*"
],
"settings": {
"index": {
"number_of_replicas": "3"
}
}
}
kind: ConfigMap
metadata:
name: es-template
namespace: kube-system
---
ConfigMapをk8sではpodからストレージボリュームとして参照することが出来ます。
volumes:
- name: es-template
configMap:
name: es-template
k8sのvolumeオブジェクトはConfigMapの名前を指定してボリュームとしてPodから認識させます。
このオブジェクトをマウントします。
volumeMounts:
- name: es-template
mountPath: /host
readOnly: true
fluent-plugin-elasticsearchのILMの設定を入れていきます。
# ILM parameters
# ==============
- name: FLUENT_ELASTICSEARCH_ENABLE_ILM
value: "true"
- name: FLUENT_ELASTICSEARCH_ILM_POLICY
value: '{ "policy": { "phases": { "hot": { "min_age": "0ms", "actions": { "rollover": { "max_age": "1d", "max_size": "5g
b" } } }, "delete": { "min_age": "2d", "actions": { "delete": {}}}}}}'
- name: FLUENT_ELASTICSEARCH_TEMPLATE_FILE
value: /host/index_template.json
- name: FLUENT_ELASTICSEARCH_TEMPLATE_NAME
value: "logstash-default"
上記の設定を入れればElasticsearchのILMの機能を有効化する為に必要な設定が入れられました。
変更の全体はこのコミットで見ることができます。
実際に適用してみる
適用する前に、以下の設定を実際のElasticsearchが動いているサーバーの値に書き換えておいてください。
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch-master.default.svc"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
この記事で実際に使用しているElasticsearchとそのデプロイ方法の概要
この記事で使用しているElasticsearchはElastic社がメンテナンスしているhelm chartsの7.8.0タグを用いてminikubeで作成したk8sにデプロイしました。
k8sの外からElasticsearchのAPIを叩けるように9200ポートのポートフォワードを設定しておきます。
$ kubectl port-forward svc/elasticsearch-master 9200
Forwarding from 127.0.0.1:9200 -> 9200
Forwarding from [::1]:9200 -> 9200
...
別のターミナルからElasticsearchの応答を確認します。
$ curl localhost:9200
{
"name" : "elasticsearch-master-2",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Vskz9aTjTZSCg8klQMz5mg",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Elasticsearch v7.8.0が動作していることが確認できました。
kubectlを用いて実際に適用
では、kubectlで実際に適用してみます。
$ kubectl apply -f fluentd-daemonset-elasticsearch.yaml
configmap/es-template created
daemonset.apps/fluentd created
Podが動作しているかを確認します。
$ kubectl get pods -n=kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-pswng 1/1 Running 1 13d
etcd-minikube 1/1 Running 0 6d1h
fluentd-hqh9n 1/1 Running 0 7s
kube-apiserver-minikube 1/1 Running 0 6d1h
kube-controller-manager-minikube 1/1 Running 1 13d
kube-proxy-kqllr 1/1 Running 1 13d
kube-scheduler-minikube 1/1 Running 1 13d
storage-provisioner 1/1 Running 3 13d
FluentdのDaemonSetが動作しているのを確認できました。
Fluentdが正常に動いているかをPodのログを見て確認してみます。
$ kubectl logs fluentd-hqh9n -n=kube-system
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-dedot_filter' version '1.0.0'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-detect-exceptions' version '0.0.13'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-elasticsearch' version '4.1.1'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-grok-parser' version '2.6.1'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-json-in-json-2' version '1.0.2'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-kubernetes_metadata_filter' version '2.3.0'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-multi-format-parser' version '1.0.0'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-prometheus' version '1.6.1'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-record-modifier' version '2.0.1'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-rewrite-tag-filter' version '2.2.0'
2020-07-22 08:06:15 +0000 [info]: gem 'fluent-plugin-systemd' version '1.0.2'
2020-07-22 08:06:15 +0000 [info]: gem 'fluentd' version '1.11.1'
2020-07-22 08:06:16 +0000 [info]: using configuration file: <ROOT>
...
<snip>
...
2020-07-22 08:06:16 +0000 [info]: starting fluentd-1.11.1 pid=6 ruby="2.6.6"
2020-07-22 08:06:16 +0000 [info]: spawn command to main: cmdline=["/usr/local/bin/ruby", "-Eascii-8bit:ascii-8bit", "/fluentd/vendor/bundle/ruby/2.6.0/bin/fluentd", "-c", "/fluentd/etc/fluent.conf", "-p", "/fluentd/plugins", "--gemfile", "/fluentd/Gemfile", "-r", "/fluentd/vendor/bundle/ruby/2.6.0/gems/fluent-plugin-elasticsearch-4.1.1/lib/fluent/plugin/elasticsearch_simple_sniffer.rb", "--under-supervisor"]
2020-07-22 08:06:16 +0000 [info]: adding match in @FLUENT_LOG pattern="fluent.**" type="null"
2020-07-22 08:06:16 +0000 [info]: adding filter pattern="kubernetes.**" type="kubernetes_metadata"
2020-07-22 08:06:16 +0000 [info]: adding match pattern="**" type="elasticsearch"
2020-07-22 08:06:17 +0000 [info]: adding source type="systemd"
2020-07-22 08:06:17 +0000 [info]: adding source type="systemd"
2020-07-22 08:06:17 +0000 [info]: adding source type="systemd"
2020-07-22 08:06:17 +0000 [info]: adding source type="prometheus"
2020-07-22 08:06:17 +0000 [info]: adding source type="prometheus_output_monitor"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: adding source type="tail"
2020-07-22 08:06:17 +0000 [info]: #0 starting fluentd worker pid=18 ppid=6 worker=0
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-scheduler-minikube_kube-system_kube-scheduler-986d31752d921b9cee830917de6372781bd418c4674e7c890ef2ccb082292f50.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/elasticsearch-master-1_default_configure-sysctl-f8b971b868b6536e084453d8890a7677640446a20b8dc6397ed7715ada823be5.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/fluentd-hqh9n_kube-system_fluentd-65a884bccf20d3134d96f836a3a1a9e1116bee9fd01a8298206b54baf9340f84.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/elasticsearch-master-1_default_elasticsearch-6393ceacc5dc158689f5f4c20a3b072c91badab6974469e2652882eadc8b0964.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/elasticsearch-master-0_default_elasticsearch-7a47537855db7869b905cff73434348b7244a3f2a0a2f31b7703fdff864d3838.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/storage-provisioner_kube-system_storage-provisioner-1a2e641e4dfa4470903315c22c369cd02f43b819a44911130cb775b771bf2f42.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-proxy-kqllr_kube-system_kube-proxy-c756169c6e4a9c348719703e49630442f48327552cbaf33a7a61bf6d60ffa3f8.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/elasticsearch-master-0_default_configure-sysctl-5fee5b507865277bf15f8f5412d72f977038b21e657fa39d51f73705edfe8b6b.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-scheduler-minikube_kube-system_kube-scheduler-fdec557596b5c9c38040b9a04753b3407fa51f3e07bd1fea441b8c72bcc33f6a.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-proxy-kqllr_kube-system_kube-proxy-68c7040be16381fa6e8179312482f36c521bb0588053c879138199e2c89deca5.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/etcd-minikube_kube-system_etcd-8ece6d2d408533810f2bc33e9aeeb534ea2781259c8046331b297c446ec24fe9.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-apiserver-minikube_kube-system_kube-apiserver-ffa76a89be8bf37a82e68a36ea165d4db957b2156c277131f592d7b1b9497279.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/coredns-66bff467f8-pswng_kube-system_coredns-3f5612e80916072da46574a47f2b782dce33a536c1fa62d95450d1673ff63105.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-controller-manager-minikube_kube-system_kube-controller-manager-015b2b7520797e279dd4783eeb68fa8b8a26db6ecc1d684f67bfdc13411791e3.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-controller-manager-minikube_kube-system_kube-controller-manager-9a1b2e08d497b4ca2d144e42972b23fad15bcc1beb996a2b8e6fab0aee3999c0.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/elasticsearch-master-2_default_elasticsearch-c179b54e4fdddbb20068269b75cd88325658c98847d6d906d3a4a954860885af.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/coredns-66bff467f8-pswng_kube-system_coredns-3a7f59d8a9cec5ed207b061d89853cd19c3f2388a09a628c590d079c76af0323.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/storage-provisioner_kube-system_storage-provisioner-73c205f99d913ad3915df4004aeab5a03a549c7d00dbc47288bfec9cdedfdcf8.log
2020-07-22 08:06:17 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/elasticsearch-master-2_default_configure-sysctl-a4ffd4fa272b2eaaa4bb6daf8e2618ee109fdb9aba51ce9130226823f1be08a0.log
2020-07-22 08:06:17 +0000 [info]: #0 fluentd worker is now running worker=0
#0 fluentd worker is now running worker=0 となるので正常に動作しています。
動作させていくらか経ったElasticsearchのインデックスの状態を確認します。
$ curl localhost:9200/_cat/indices
green open logstash-default-2020.07.22-000004 1BNxJGy2R_u2ETFog8hI5g 1 3 0 0 624b 208b
green open logstash-default-2020.07.25-000002 yesiqdW4Qdi_PD5JEGwctw 1 3 0 0 624b 208b
green open logstash-default-2020.07.27-000002 y0-NGO_3SmmcRRnLNNy9cw 1 3 0 0 624b 208b
green open logstash-default-2020.07.22-000003 B8Z41XVvTpCIjrLewEutMA 1 3 61 0 153.5kb 51.1kb
green open logstash-default-2020.07.21-000001 5JzBvzkgSve-pJBOl-_AOA 1 3 3662 0 4.5mb 1.5mb
green open logstash-default-2020.07.22-000002 hsojlNScTOCaMDKCLlTEjQ 1 3 0 0 624b 208b
green open logstash-default-2020.07.25-000001 L9mPpFjrSYmex27-oUlqsQ 1 3 22798 0 17mb 5.6mb
green open logstash-default-2020.07.28-000001 kYvZ7R_fSVaXcIMBdP7OgA 1 3 132 0 518.8kb 185kb
green open logstash-default-2020.07.27-000001 CJTNpX4lQf6frlc5v1aHIg 1 3 62061 0 45.2mb 15.1mb
green open logstash-default-2020.07.25-000003 g_oSzQTRS42Pn5DZm8NSMA 1 3 0 0 624b 208b
logstash-default-2020.07.22-000001のインデックスは作成されてから2日以上経っているので消されていることがわかります。
インデックスがILMで管理されているかどうかを確認します。
$ curl localhost:9200/logstash-2020.07.28/_ilm/explain | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 550 100 550 0 0 36666 0 --:--:-- --:--:-- --:--:-- 36666
{
"indices": {
"logstash-default-2020.07.28-000001": {
"index": "logstash-default-2020.07.28-000001",
"managed": true,
"policy": "logstash-policy",
"lifecycle_date_millis": 1595898121210,
"age": "4.37h",
"phase": "hot",
"phase_time_millis": 1595898121544,
"action": "rollover",
"action_time_millis": 1595898216494,
"step": "check-rollover-ready",
"step_time_millis": 1595898216494,
"phase_execution": {
"policy": "logstash-policy",
"phase_definition": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_size": "5gb",
"max_age": "1d"
}
}
},
"version": 7,
"modified_date_in_millis": 1595398857585
}
}
}
}
"managed": true,とあるため、このインデックスはILMにより管理されています。
試しにElasticsearchに検索リクエストを飛ばしてみましょう。
$ curl -XGET -H "Content-Type: application/json" localhost:9200/logstash-2020.07.28/_search -d '{"size": 2, "sort": [{"@timestamp": "desc"}]}' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2502 100 2457 100 45 5906 108 --:--:-- --:--:-- --:--:-- 6014
{
"took": 391,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 242,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "logstash-default-2020.07.28-000001",
"_type": "_doc",
"_id": "OXzek3MBhNn_Y01M22q7",
"_score": null,
"_source": {
"log": "2020-07-28 05:21:57 +0000 [info]: #0 [filter_kube_metadata] stats - namespace_cache_size: 2, pod_cache_size: 2, namespace_cache_api_updates: 4, pod_cache_api_updates: 4, id_cache_miss: 4\n",
"stream": "stdout",
"docker": {
"container_id": "65a884bccf20d3134d96f836a3a1a9e1116bee9fd01a8298206b54baf9340f84"
},
"kubernetes": {
"container_name": "fluentd",
"namespace_name": "kube-system",
"pod_name": "fluentd-hqh9n",
"container_image": "fluent/fluentd-kubernetes-daemonset:v1.11.1-debian-elasticsearch7-1.3",
"container_image_id": "docker-pullable://fluent/fluentd-kubernetes-daemonset@sha256:af33317d3b8723f71843b16d1721a3764751b1f57a0fe4242a99d1730de980b0",
"pod_id": "fdfd5807-8164-4907-a1a9-9b782c3eb97e",
"host": "minikube",
"labels": {
"controller-revision-hash": "57997fd64d",
"k8s-app": "fluentd-logging",
"pod-template-generation": "1",
"version": "v1"
},
"master_url": "https://10.96.0.1:443/api",
"namespace_id": "5c1df0cc-d72b-4c24-a4af-a8d595d62713"
},
"@timestamp": "2020-07-28T05:21:57.002062084+00:00",
"tag": "kubernetes.var.log.containers.fluentd-hqh9n_kube-system_fluentd-65a884bccf20d3134d96f836a3a1a9e1116bee9fd01a8298206b54baf9340f84.log"
},
"sort": [
1595913717002
]
},
{
"_index": "logstash-default-2020.07.28-000001",
"_type": "_doc",
"_id": "gWLek3MByRVHYKQQ2yC5",
"_score": null,
"_source": {
"log": "2020-07-28 05:21:56.801939 I | mvcc: finished scheduled compaction at 59275 (took 3.825907ms)\n",
"stream": "stderr",
"docker": {
"container_id": "8ece6d2d408533810f2bc33e9aeeb534ea2781259c8046331b297c446ec24fe9"
},
"kubernetes": {
"container_name": "etcd",
"namespace_name": "kube-system",
"pod_name": "etcd-minikube",
"container_image": "k8s.gcr.io/etcd:3.4.3-0",
"container_image_id": "docker-pullable://k8s.gcr.io/etcd@sha256:4afb99b4690b418ffc2ceb67e1a17376457e441c1f09ab55447f0aaf992fa646",
"pod_id": "27093604-c8b7-4b22-a0df-c7eebe63afb3",
"host": "minikube",
"labels": {
"component": "etcd",
"tier": "control-plane"
},
"master_url": "https://10.96.0.1:443/api",
"namespace_id": "5c1df0cc-d72b-4c24-a4af-a8d595d62713"
},
"@timestamp": "2020-07-28T05:21:56.802153342+00:00",
"tag": "kubernetes.var.log.containers.etcd-minikube_kube-system_etcd-8ece6d2d408533810f2bc33e9aeeb534ea2781259c8046331b297c446ec24fe9.log"
},
"sort": [
1595913716802
]
}
]
}
}
確かにElasticsearchにk8s内部で発生したログがストアされていることが確認出来ました。
まとめ
FluentdのDaemonSetにより、k8s内部のログをILMを有効化してElasticsearchにストアするやり方を解説しました。
この記事の方法でElasticsearchのILMを有効化する場合、helmを使っているのであればElasticvsearchをデプロイする際に注意点があります。helmの公式リポジトリでデプロイできるElasticsearchは古く、
Elasticsearchの開発元のものを使ってhelmでElasticsearchのクラスターをデプロイしてください。
また、記事中で使用しているILMのポリシーは2日経ったらインデックスを消去するという単純なものですが、実際のプロダクション環境ではhotのあとにwarmやcold状態を挟んでdeleteに移行するポリシーを作成するよう検討してください。
当社では、お客さまからの技術的なご質問・ご依頼に有償にて対応するFluentdサポートサービスを提供しています。Fluentd/Fluent Bitをエンタープライズ環境において導入/運用されるSIer様、サービス提供事業者様は、お問い合わせフォームよりお問い合わせください。
*1 fluent-plugin-elasticsearch v4.1.1でILM関連のバグは直しました。
Apache Arrowの最新情報(2020年7月版)
Apache ArrowのPMC(Project Management Commitee、プロジェクト管理チームみたいな感じ)のメンバーの須藤です。
みなさんはApache Arrowを知っていますか?最近、ついに1.0.0がリリースされたんですよ。私がApache Arrowの最新情報をまとめた2018年9月から毎年「今年中に1.0.0がでるぞ!」と言っていた1.0.0がついにリリースされたんです!
1.0.0を機に安心して使えるようになります。(どう安心なのかは後で説明します。)
Apache Arrowはすでにデータ処理界隈で重要なコンポーネントになりつつありますが、数年後にはもっと重要になっているだろうプロジェクトです。データ処理界隈に興味がある人は知っておくと役に立つはずなので毎年Apache Arrowの最新情報をまとめています。1.0.0がリリースされたので2020年7月現在の最新情報を紹介します。
私は、PMCの中では唯一の日本人で、コミット数は2番目に多いので、日本ではApache Arrowのことをだいぶ知っている方なはずです。日本語でのApache Arrowの情報があまりないので日本語で紹介します。
ちなみに、英語ではいろいろ情報があります。有用な情報源はApache Arrowの公式ブログや公式メーリングリストやそれぞれの開発者のブログ・発表などです。開発者のブログの中ではUrsa Labs Blogの隔月の開発レポート(最近は隔月の開発レポートコーナーがありませんが…)がオススメです。Ursa Labsはスポンサーを集めてフルタイムでApache Arrowの開発をしている非営利の組織です。(という説明でそんなに間違っていないはず。)
この記事ではそれらの情報へのリンクも示しながら最新情報を紹介するので、ぜひ英語の情報も活用してください。
Apache Arrowが実現すること
Apache Arrowが実現することはプロジェクト開始当初から変わっていないので、Apache Arrowの必要性から知りたいという方はApache Arrowの最新情報(2018年9月版)を参照してください。まとめると次の通りです。
Apache Arrowは大量のデータを効率的にメモリー上で処理することを目指しています。そのためにしていることは次の通りです。
- データ交換・高速処理しやすいApache Arrowフォーマットの仕様を定義
- 各種言語用のApache Arrowフォーマットを読み書きするライブラリーを開発
- 大量のメモリー上のデータを高速処理するためライブラリーを開発
Apache Arrowが向いている用途は次の通りです。
- 大量データの交換
- メモリー上での大量データの分析処理
実は、1.0.0の前からすでにApache Arrowは利用され始めています。
たとえば、Apache SparkはJVMとPython・R間でのデータ交換にApache Arrowを使って10倍以上高速化しています。(データ量が大きいほど高速化できます。)
- Speeding up PySpark with Apache Arrow
- Speeding up R and Apache Spark using Apache Arrow | Apache Arrow
- この記事はsparklyrの話ですが、SparkRでもApache Arrowを使って高速化できます。
Amazon AthenaはApache ArrowフォーマットでAmazon Athenaにデータを提供できる機能を提供しています。
GroongaはApache Arrowフォーマットでのデータロードと検索結果の返却に対応しています。
Apache Arrowの現状
それでは、2020年7月現在のApache Arrowについて説明します。
まず、2020年7月24日にApache Arrow 1.0.0がリリースされました。1.0.0の特筆する点はApache Arrowフォーマットの安定性です。
Apache Arrowフォーマットの安定性
フォーマットの安定性というは、互換性が高い低いとか問題が多い少ないとかいう話ではなく、フォーマットの互換性をどう維持する方針なのかという話です。
これまではたまに互換性が壊れていました。たとえば、Apache Arrow 0.15.0でデータをアラインするためにパディングするように変更しました。これにより0.15.0で生成したデータを0.15.0より前のバージョンで読めなくなりました。Apache SparkはApache Arrow 0.15.0より前からApache Arrowに対応していたので、Apache Sparkでこの問題に遭遇したケースが多かったはずです。
1.0.0からは後方互換性と前方互換性を次のように維持します。セマンティックバージョニングに従っています。簡単に言うと、メジャーバージョンが上がったら互換性はない、マイナー・パッチバージョンが上がっただけなら互換性がある、です。互換性が壊れるのは大変なのはわかっているのでできるだけメジャーバージョンが上がらないように運用する予定ではあります。
注意する点は「Apache Arrowフォーマットのバージョン」と「Apache Arrowライブラリーのバージョン」は別だということです。Apache Arrowライブラリー2.3.1はApache Arrowフォーマット1.1.2を使うということが起こりうるということです。
後方互換性:
-
新しいフォーマットバージョンに対応したライブラリーでは古いフォーマットバージョン用に生成したすべてのデータを読める
- 例:フォーマットバージョン1.0.0用に生成したデータはフォーマットバージョン2.0.0に対応したライブラリーで読める
-
フォーマットバージョンのメジャーバージョンが変わらない限り、新しいフォーマットバージョン用に生成したデータは古いフォーマットバージョンに対応したライブラリーでも読める
- 例:フォーマットバージョン1.3.0用に生成したデータはフォーマットバージョン1.0.0に対応したライブラリーで読める
- 例:フォーマットバージョン2.0.0用に生成したデータはフォーマットバージョン1.0.0に対応したライブラリーで読めるかもしれないし読めないかもしれない(読めることは保証しない。後述の前方互換性も参照。)
前方互換性:
- 新しいフォーマットバージョン用に生成したデータは、古いフォーマットバージョンに対応したライブラリーでは読める、あるいは、読めないことを検出できる(おかしく読むことはない)
- 例:フォーマットバージョン2.0.0用に生成したデータは、フォーマットバージョン1.0.0に対応したライブラリーで読める
- 例:フォーマットバージョン2.0.0用に生成したデータは、フォーマットバージョン1.0.0に対応したライブラリーで読めない場合は読めないことを検出する(おかしく読まない)
- フォーマットバージョンのマイナーバージョンが挙がった場合は新しい機能が追加される
- 例:フォーマットバージョン1.1.0でフォーマットバージョン1.0.0ではなかった型を追加
- 新しい機能を使っていない場合は新しいフォーマットバージョン用に生成したデータを古いフォーマットバージョンに対応したライブラリーで読める
- 例:フォーマットバージョン1.1.0用に生成したデータだが1.0.0の機能しか使っていない場合はフォーマットバージョン1.0.0に対応したライブラリーで読める
参考:Format Versioning and Stability
なお、1.0.0のリリース前にいつもより多くフォーマットの変更が入っています。たとえば、データをLZ4・Zstandardで圧縮する機能が入っています。同一ホスト上でメモリー上のデータをそのまま交換している場合(たとえばmmap()で同じアドレスを共有している場合)は圧縮・展開で速度が落ちるので意味はありませんが、Apache Arrow Flightで異なるホスト間でデータを交換したり、Featherフォーマットとしてデータをストレージに保存する場合はI/Oが減って高速になる場合があります。他の変更点はApache Arrow 1.0.0のリリースアナウンスを参照してください。
Featherフォーマットと聞いてびっくりした人のために補足しておくと、Featherフォーマットバージョン1は非推奨のままです。Featherフォーマット2はApache Arrow IPCファイルフォーマットのことです。Apache ArrowライブラリーのC++実装ではFeatherフォーマットバージョン1もバージョン2も読み書きできます。
フォーマットのバージョンを説明したのでライブラリーのバージョンも説明します。
Apache Arrowライブラリーのバージョン
Apache Arrowライブラリーのバージョンもセマンティックバージョニングに従います。従うのですが、しばらくは毎回メジャーバージョンが上がる予定です。つまり、1.0.0の次のバージョンは2.0.0です。
Apache Arrowライブラリーはまだまだ活発に機能追加・変更・修正をしているため、互換性を維持しながらでは開発スピードが落ちてしまうことを懸念してこうなっています。
今のところApache Arrowライブラリーは3ヶ月に1回程度のペースでリリースされているので今年中に2.0.0がでて、来年には3.0.0が出るようなペースです。
フォーマットのバージョンのところでも説明しましたが、ライブラリーのバージョンとフォーマットのバージョンは別々に管理し、フォーマットの(メジャー)バージョンはできるだけあげない(互換性を壊さない)方針で運用します。そのため、ライブラリーのバージョンとフォーマットのバージョンはどんどん離れていきます。たとえば次のような感じです。
- 1.0.0の次のリリース
- ライブラリーのバージョン:2.0.0
- データフォーマットのバージョン:1.0.0
- 1.0.0の次の次のリリース
- ライブラリーのバージョン:3.0.0
- データフォーマットのバージョン:1.0.0
Apache Arrowライブラリーは頻繁に互換性が壊れる前提になるのでライブラリーを利用する人はセマンティックバージョニングに合わせて依存情報を設定したほうがよいかもしれません。たとえば、PyPIからインストールするならpyarrow==1.*と指定して同じメジャーバージョンを使うようにするといった具合です。
ただ、古いバージョンを使い続けることになるとApache Arrowライブラリーの高速化や新機能の恩恵を受けられないので、定期的にアップグレードした方がよいです。クリアコードではApache Arrow関連の開発のサポートサービスを提供しているので、Apache Arrowを使いたいけど自分たちで対応し続けるのは不安という方はご相談ください。Apache Arrowに詳しい会社としてお手伝いします。(宣伝)
Apache Arrowライブラリーはいろんな言語ですぐに使える(「batteries-included」と自分たちで言うこともある)開発プラットフォームを提供しようとしています。1.0.0で大きく変わったバージョニングの説明をしたので、次は各言語の現状を説明します。
各言語ごとのApache Arrowライブラリーの現状
Apache Arrowの最新情報をまとめはじめて3年目になりますが、毎年、ソースを見ながら各言語の状況をまとめていました。が、それも去年で終わりです。公式ドキュメントでまとめはじめたのです!
表を見るとわかるのですが、Apache Arrowの仕様をすべて満たした実装はまだありません。C++実装が一番実装しているのですが、それでもいくつか未実装の機能があります。(表の列にないC・Python・R・Ruby実装はC++実装のバインディングなので実装範囲はC++実装に準じます。)
次に実装範囲が多いのがJava実装でC++実装ほどではないですがほとんど網羅しています。
Go・JavaScript・C#・Rust実装は基本機能はほぼ網羅しているといった感じです。(Rust実装に1つもチェックが入っていないのはまだ誰も埋めていないからなだけで、Rust実装はアクティブに開発が進んでいる実装の1つです。)
自分が使いたい言語の実装に自分が使いたい機能は実装されていたでしょうか?もし、まだ実装されていなくても大丈夫です。実装すればいいのです!Apache Arrowは「みんなバラバラに基盤を実装するんじゃなくて一緒に協力して基盤を実装した方がみんながうれしくなるよね!」という発想で開発が始まっています。未実装の機能があったら一緒に実装しましょう!
未実装の機能を自分たちで実装してApache Arrowを使い始めた例を紹介します。網屋さんが開発しているALogというログ収集製品ではデータのやり取りの一部にApache Arrowを検討していました。高速化のためです。しかし、C#実装にまだリスト型が実装されていませんでした。そこで、網屋の橋田さんは業務の一環としてリスト型の対応などを実装し、ALogで必要な機能を使えるようにしました。その結果、ALogでApache Arrowを使った高速化を実現できました。今後、日本でもApache Arrowの開発に参加する企業は増えていくでしょうが、網屋さんは先行している企業の1つです。
ちなみに、クリアコードは網屋さんがApache Arrowの開発に参加することを支援しました。未実装の機能を実装したいから支援して欲しいという方はご相談ください。(宣伝)
各言語の実装の状況をざっと説明したのでこの1年での変更点もざっと説明します。まずは計算関数です。
計算関数
Apache Arrowライブラリーは高速なデータ交換方法だけではなく、高速なデータ処理方法も提供しようとしています。高速なデータ処理に関しては、今のところ、2つのアプローチの開発が進んでいます。1つはGandivaという名前の式コンパイラーです。条件式や計算式をJITコンパイルして高速に実行できます。もう1つは計算関数(compute functions)と呼んでいる関数群です。計算関数は各計算処理を個別に使います。
Gandivaではユーザーがa + b * cという式を入力として実行できますが、計算関数はユーザーがa + bを実行し、その結果とcの掛け算を実行します。Gandivaの方が高レベルな機能を提供するのですが、Gandivaレベルでも計算関数が提供しているのと同レベルの機能(たとえば数値の足し算)を提供しているので、重複している部分があります。これらの機能の棲み分けが今後どうなってくるのかは。。。私もよくわかっていません。なんどか議論はされているのですが、結局どうなるのかピンときていませんし、現時点ではまだ目立った動きもありません。
参考:Compute kernels and Gandiva operators
Gandivaに関してはこの1年でそんなに目立った動きはない(使える関数は少しずつ増えていて開発は進んでいます)ので、動きがあった計算関数について説明します。
最近、計算関数の仕組みが書き直されました。これまでは静的に使う(コンパイル時にどの関数を使うか決める)方式だったのですが、動的に使う(実行時にどの関数を使うか決める)方式になりました。具体的にどう使い方が変わったかと言うと、実行時に名前で関数を探して、見つけた関数を実行するようになりました。名前は単なる文字列なので実行時に生成できます。
使い方が変わってどううれしいかピンとこないと思うので、ユーザー視点でうれしいこと例を示します。たとえば、PythonユーザーはC++実装に計算関数が増えたらPython実装を変えずに新しい計算関数を使えます。これまでは、C++実装に計算関数が増えたらPython実装にもその計算関数を使えるようにする処理が実装されないと使えませんでした。C++実装に「すごい計算関数」が追加されたらすぐにPythonスクリプトから「すごい計算関数」を使えるということです。
現時点では、C++実装とPython実装は同じタイミングでリリースされ、Python実装の漏れはほとんどありませんが、今後、C++実装にプラグインの仕組みができた場合はかなりうれしくなります。自分でC++で実装した計算関数をすぐにPythonスクリプトから使えるようになります。(伝わる?)
まだ計算関数をプラグインで追加できるようにするという話はあがっていませんが、別の機能をプラグインで拡張できるようにしない?という提案はあがっています。近い将来、プラグインの仕組みができるかもしれません。
計算関数もだいぶ増えました。複数カラムでのソートなど足りない機能はまだあるのですが、どんどん増えています。現在使える関数については計算関数のドキュメント(再掲)を参照してください。
計算関数の仕組みが書き直されたタイミングで計算関数を実装しやすくなっています。計算関数を実装したくなったらcpp/src/arrow/compute/の下をのぞいてください。
高速なデータ処理に関することだけでなく、高速なデータ交換に関することでも追加機能があったので説明します。
Cデータインターフェイス
Apache Arrowはネットワーク越し・プロセス越しなどいろいろなスケールでの高速なデータ交換を実現しようとしています。この1年でCデータインターフェイスという、同一プロセス内の別システム間でのデータ交換用のインターフェイスが増えました。
Apache Arrowを使うためには公式の実装を使うか自分たちが必要な分だけの自分たちの実装を作る必要があります。前述の通り、公式の実装はしばらく頻繁に互換性が壊れる想定なのでアップグレードに追従するコストが少なからず発生します。一方、独自に実装すると依存ライブラリーが増えなかったりアップグレードに追従するコストはありませんが、実装・メンテナンスはそれなりに大変です。(ちなみに、PG-StromのArrow_fdwは後者のアプローチです。)
Cデータインターフェイスを使うと、Apache Arrowの実装に依存せずに同一プロセス内の別システムとApache Arrowデータ(カラムナーデータ)を交換できます。ただし、単にデータを交換できるだけでApache Arrowフォーマットでの入出力や、Apache Arrowデータに対する高速なデータ処理機能はありません。たとえば、前述のArrow_fdwはApache Arrowフォーマットでの入出力があるのでCデータインターフェイスは使えません。
ユースケースの1つは、同一プロセス名で別言語が動いていてそれらの言語間でデータ交換したいケースです。たとえば、Introducing the Apache Arrow C Data Interface | Apache ArrowではRと同じプロセス内でPythonを動かし、RとPythonでデータをやり取りする例を紹介しています。(Cデータインターフェイス単体でではなく、Apache Arrowライブラリーと一緒に使用しています。)
私は、SQLite3がCデータインターフェイスでデータを提供するAPIを用意するとうれしいケースがあるのではないかと考えています。
CデータインターフェイスはCの構造体定義・関数定義・仕様だけを提供しています。この定義をコピーして、仕様に合わせて動くようにすればApache Arrowデータを交換できます。詳細はCデータインターフェイス(再掲)を参照してください。
この1年の大きな機能面での変更を説明したので、次はビルド関連・パッケージ関連について説明します。
C++実装のビルドオプション
Apache Arrowライブラリーはすぐに使える(batteries-included)開発プラットフォームを提供しようとしているため、たくさんの有用な機能が詰め込まれています。すべての機能を自前で実装しているわけではなく、すでに有用な実装がある場合はライブラリーとしてその機能を組み込んで提供します。そのため、フル機能のApache Arrowライブラリーには依存ライブラリーが多いです。
しかし、すべてのユースケースでフル機能のApache Arrowライブラリーが必要なわけではありません。そのため、C++実装では必要に応じて各機能をオン・オフできるようになっています。
もともと、デフォルトではほぼオンになっていたのですが、デフォルトでオフになりました。必要に応じてオンにするようになりました。1.0.0がリリースされたから久しぶりに自分でビルドしてみるか!という人はCMakeのオプションを再確認してください。
依存ライブラリーを動的にリンクするか静的にリンクするかも個別に選べるようになりました。(選べるようにする作業がそろそろ完了しそうです。)
また、静的にリンクしたApache Arrowライブラリーを簡単に使えるようになりました。(使えるようにする作業がそろそろ完了しそうです。)
静的にリンクしたApache Arrowライブラリーをリンクする場合は、Apache Arrowライブラリーにリンクするだけではなく、Apache Arrowライブラリーに静的にリンクしている依存ライブラリーも一緒にリンクする必要があります。これまではユーザーが依存ライブラリーを自分で追加しないといけなく、現実的には使えない状態だったのが、次の方法でユーザーが特になにもしなくても使えるようになりました。
Apache Arrowライブラリーにバンドルされている依存ライブラリーを使った場合:
- バンドルされている依存ライブラリーをすべてまとめた
libarrow_bundled_dependencies.aを生成してインストール - Apache ArrowライブラリーのCMakeパッケージでは必要に応じて
libarrow_bundled_dependencies.aをリンクフラグに追加- pkg-configは未対応(これを書いていて対応するのを忘れていたことに気づいた)
システムの依存ライブラリーを使った場合:
- Apache ArrowライブラリーのCMakeパッケージが必要に応じて依存ライブラリーの情報を集めてリンクフラグに追加(実装中)
- pkg-configは未対応(↑の実装が終わったらやらないと)
このあたりの話や次に説明するパッケージ関連の話も書いてあるMaking Arrow C++ Builds Simpler, Smaller, and Faster | Apache Arrowも読んでみてください。
パッケージ関連
パッケージ関連もこの1年でさらによくなりました。
1年ほど前はPython用のwheelパッケージはもうメンテナンスできないよ…となっていたのですが、再び頑張ってメンテナンスするようになりました。メンテナンスを諦めていた理由は次の通りでした。
- やる人がいない
- 開発している人がやると時間がとられて開発が進まない
- wheelのメンテナンスをするより開発を進める方が優先度が高い
wheelのメンテナンスのためにApache Arrowの開発に参加する人もいたのですが、なかなかタスクを完了するところまでいけませんでした。たとえば、Python 3.8対応のケースです。前述の通りApache Arrowライブラリーは依存関係が多く、すべての依存ライブラリーを同梱しないといけないwheelの作成は難しい(というか面倒)です。それに加えて、新しいバージョンのPythonに対応するのはまた難しい(というか面倒)だったのです。Python 3.8対応については私が引き取って完了させました。(どーん!)
Python 3.8対応の後は私も含めてコアの機能を作っている人たちがちまちま手を入れながらメンテナンスしています。
なお、wheelのメンテナンスに時間を割くようになったのはwheelユーザーが多かったからでした。(月間700万ダウンロードとかそういう感じ。)
1.0.0ではGandiva対応が削除されました。これはwheelのサイズを減らすためです。今後はpyarrowにすべてを入れるのではなくサブパッケージにわけて必要な人が必要な機能をインストールできるようにする予定です。wheelユーザーの人はこういう作業とかで一緒にメンテナンスしませんか?
Python実装ののwheel以外のパッケージもよくなっています。
Debian GNU/Linux、Ubuntu、CentOS、Amazon Linux用のパッケージはARM用のパッケージも提供するようになりました。(私も結構作業しました!)
MSYS2のパッケージではGandivaを使えるようになりました。Homebrewでも有効にしたかったのですが、libstdc++のリンクの問題があって有効にできませんでした。解決策はあるので次のリリースでは有効にできるといいな。MSYS2とHomebrewのパッケージでGandivaを有効にするために@naitohと私で最新のLLVMでもGandivaを使えるようにする作業を進めていました。1.0.0に間に合ってよかった。
R実装のパッケージもインストールしやすくなっています。R実装はC++実装のバインディングなのでC++実装が必要なのですが、ビルド済みのC++実装を使えるケースを増やしています。C++実装のビルド時に問題が発生することが多いので、これで問題が減るはずです。
インストールページの説明を更新できていないのですが、C#実装のパッケージが「オフィシャル」扱いになりました。Apache ArrowのPMCが投票して受理されたものが「オフィシャル」扱いなのですが、これまではC#実装のソースだけが「オフィシャル」扱いでビルド済みのパッケージは「アンオフィシャル」扱い(投票されていない)でした。
次の1年でRuby実装のパッケージも「オフィシャル」扱いにしたいな。
まとめ
2020年7月時点のApache Arrowの最新情報を、2019年9月からの差分という形でまとめました。Apache Arrowは1.0.0がついにリリースされたことが大きなニュースでした。1.0.0リリースによってデータ処理界隈で重要なコンポーネントになることでしょう。日本でもApache Arrowのことを知っている人が増えるといいと思うので日本語でまとめました。Apache Arrowを使う人が増えるといいなぁと思います。さらに言えば開発に参加する人も増えるといいなぁと思います。
私が知っていることはまとめたつもりですが、もしかしたらカバーできていない話があるかもしれません。もし、「○○についても知りたい!」という方がいたらApache Arrowのことを日本語で話せるチャットで声をかけてください。この記事に追加します。
Apache Arrowについて講演して欲しいという方はお問い合わせください。
私はデータ処理ツールの開発という仕事をしたいと思っています。その中にはもちろんApache Arrowの開発も含まれています。一緒に仕事をしたい!(自社サービスをApache Arrow対応したいとか)という方はお問い合わせください。
- ククログの記事はCC BY-SA 4.0とGFDLのデュアルライセンスで自由に利用できます。
- クリアコードはプログラミングが楽しいソフトウェア開発者を1名募集しています。
- クリアコードは「クリアコードをいい感じにする人」を1名募集しています。
- クリアコードはフリーソフトウェア開発で培った技術力を提供しています。特にMozilla製品(Mozilla FirefoxとMozilla Thunderbird)とRubyとGroonga(全文検索)に関連した開発を得意としています。